
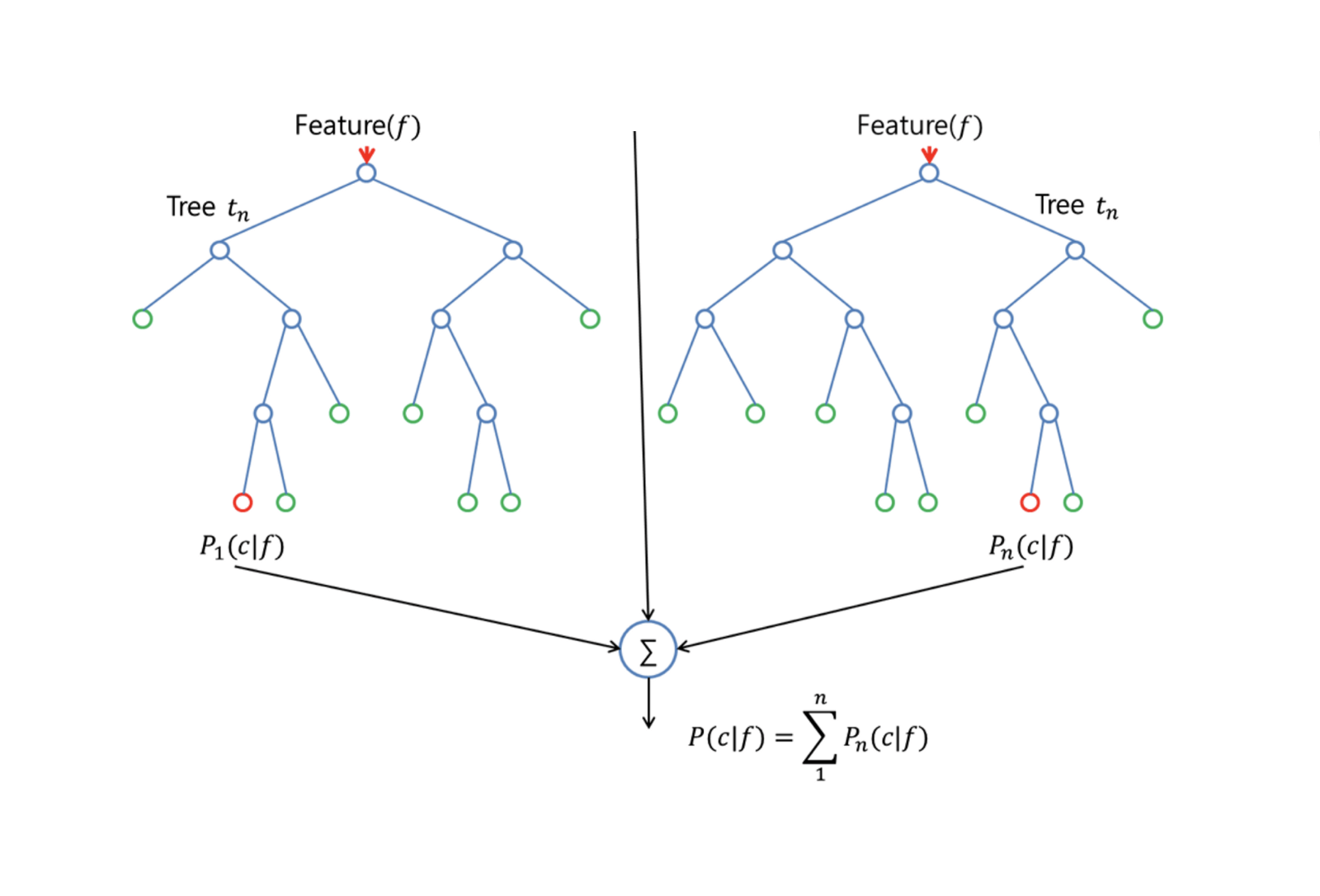
Sequence-to-sequence модель
Часто Sequence-to-sequence модели состоят из двух рекуррентных сетей: кодировщика, который обрабатывает входные данные, и декодера, который осуществляет вывод.
Читайте: Оценка глубины на изображении при помощи Encoder-Decoder сетей
Sequence-to-Sequence модели часто используются в вопросно-ответных системах, чат-ботах и машинном переводе. Такие многослойные ячейки успешно использовались в sequence-to-sequence моделях для перевода в статье Sequence to Sequence Learning with Neural Networks study.
В Paraphrase Detection Using Recursive Autoencoder представлена новая рекурсивная архитектура автокодировщика, в которой представления — вектора в n-мерном семантическом пространстве, где фразы с похожими значением близки друг к другу.
Как создать собственную нейросеть?

Прогнозирование валютного рынка Форекс с помощью искусственного интеллекта доступно «простым смертным». Нейросети участвуют в различных чемпионатах по алгоритмическому трейдингу, проводимых международными ассоциациями брокеров с 2008 года.
Собрать собственную стратегию можно на специализированных платформах: neuroshell, matlab, statistica, deductor или brainmaker. Трейдеры со знанием языка программирования могут воспользоваться специальными сервисами от Google, Microsoft, Amazon и т.д.
Чтобы максимально упростить сложные процессы обучения нейросети и выбора входных данных, трейдер может воспользоваться различными шаблонами и приложениями, собранными по типу блочного конструктора стратегий.
«Работая в лаборатории, я заметила, как много времени занимают рутинные операции»
Елена Писарчук начала свою карьеру со специальности «Биотехнология». Обучаясь в университете, она часто бывала в микробиологических лабораториях, а также работала в Институте биохимической физики РАН и Национальном исследовательском центре эпидемиологии и микробиологии имени Гамалеи. Именно здесь она нашла тему для своего будущего ML-проекта.

Елена Писарчук
Я заметила, что в лабораторных экспериментах много времени занимают рутинные операции — например, подготовка растворов, культивирование микроорганизмов и обработка результатов. Чтобы получить достоверные анализы, эксперименты нужно повторять много раз, это довольно долго. Проводя очередной эксперимент, я поняла, что обработку результатов можно автоматизировать с использованием современных технологий. Так я поняла, чему хочу учиться дальше и над какой темой буду работать.
База в биохимических анализах у меня уже была, на магистратуре главной целью было разобраться в алгоритмах компьютерного зрения и нейросетях. Чтобы выбрать инструменты для работы, я сравнила эффективность существующих типов нейросетей (DNN AlexNet, DenseNet 169, Inception и другие), а также проанализировала разные детекторы и дескрипторы особых точек. По итогу для своего проекта выбрала нейросеть DNN ResNet и алгоритм ORB.
При разработке программного комплекса я сначала написала парсер для автоматизированного сбора изображений из поисковой системы Google. С его помощью собрала более 3 тыс. изображений разных патогенных микроорганизмов. Потом алгоритм сортировки отобрал изображения с лучшим качеством, отфильтровал повторяющиеся картинки. Дальше я обучила модель классифицировать изображения с микроскопа, а для удобства использования в лабораториях сделала простой пользовательский интерфейс.

Так выглядит интерфейс для анализа изображений с микроскопа. Достаточно загрузить картинку и нажать одну кнопку, чтобы получить результат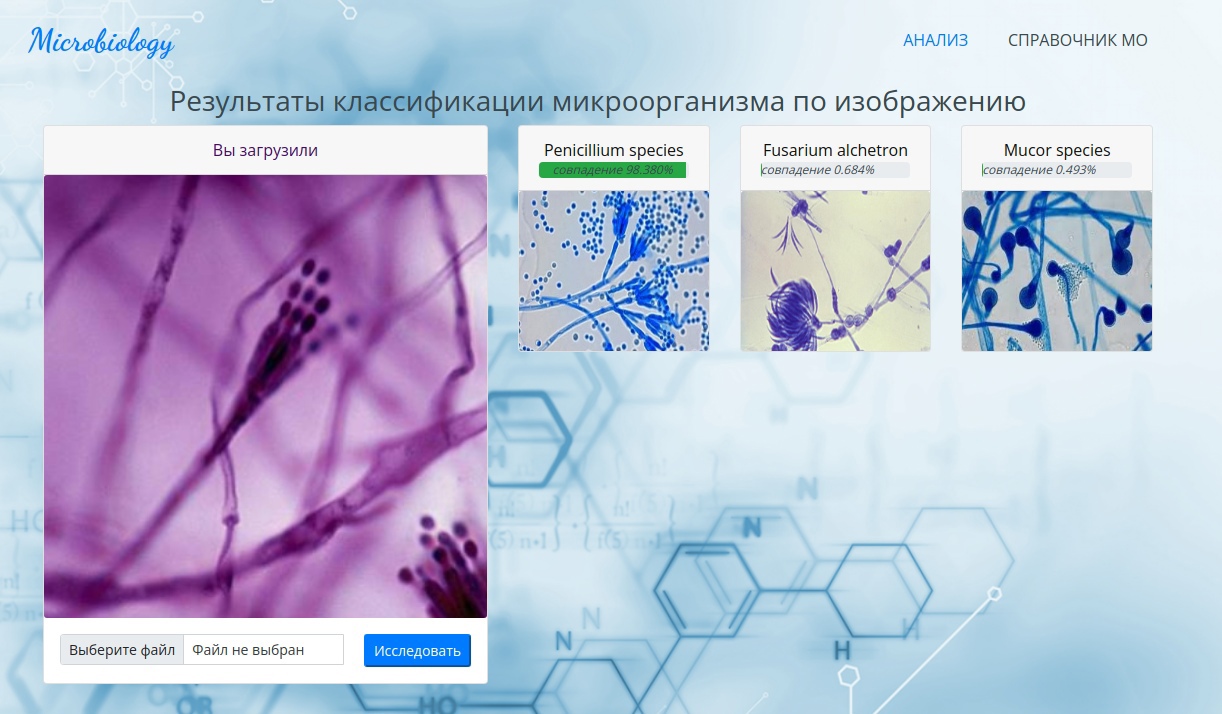
Так выглядит страница с результатами классификации
Большую часть нужных мне инструментов я получила во время обучения в магистратуре. Самой сложной частью было не программирование, а оформление результатов работы, потому что программировать для меня — это увлекательно. Программный комплекс я разрабатывала на Python. В каждой программе использован разный набор библиотек. Например, для автоматизированного сбора изображений я взяла библиотеки, которые взаимодействуют с сайтами и имитируют поведение пользователя (BS4, Selenium, Requests). Преобразование изображений проводила с использованием библиотеки CV2. В нее включены реализации моделей компьютерного зрения, в том числе алгоритм поиска ключевых точек ORB, с помощью которого определялись дубликаты в работе. Для обучения нейронной сети использовала среду разработки Google Colaboratory, для графиков визуализаций — библиотеку Matplotlib. Пользовательский интерфейс и серверную часть сайта для взаимодействия с моделью машинного обучения сделала во фреймворке Flask.
Программный комплекс сократит время на биохимические анализы крови, мочи, мазков с кожи. Это значит, что врачи смогут быстрее принимать решения о лечении, предотвращать прогрессирование болезни, а пациенты будут скорее выздоравливать.
Я планирую продолжить работу над классификатором в аспирантуре, сделать его точнее и расширить количество определяемых видов патогенов.
Сбор данных для обучения нейронной сети
Чтобы решить какую-либо задачу, используя ИНС, нужны данные, на основе которых она будет обучаться. С этой целью необходимо собрать комплекс наблюдений и указать значения входных и выходных параметров. В первую очередь нужно определить, в каком объеме потребуются сведения для обучения нейросети, и какие именно.
Как правило, в качестве объекта анализа ИНС предлагаются числовые данные в пределах ограниченного диапазона. Если предстоит работа с информацией другого формата, могут возникнуть проблемы.
Нечисловые данные в целом считаются для нейронной сети более сложным вариантом решения поставленной задачи. В качестве примера можно привести номинальные переменные типа Пол = {Муж, Жен}.
Чтобы упростить ИНС работу по анализу информации используется присвоение числовых значений. Например, нейросеть создается для оценки объектов недвижимости конкретного города, в котором каждый микрорайон имеет собственное название. На первый взгляд, проще всего добавить переменные с соответствующими словесными обозначениями. Однако это серьезно затруднит процесс обучения сети и приведет к большому проценту ошибок на выходе.
Оптимальным решением в этом случае представляется присвоение отдельным районам рейтинговых баллов, основанных не результатах экспертной оценки стоимости жилья в каждом из них.
Иными словами, достоверность итогов работы нейронной сети повышается, если нечисловые данные преобразовать в цифровой формат, а переменные, которые не поддаются этому процессу (например, фамилии), сделать незначимыми для анализа данных.
Количество наблюдений, достаточное для получения точных результатов, – еще один сложный вопрос, который приходится решать создателям нейросетей. Если вспомнить элементарное эвристическое правило, можно отталкиваться от того, что число наблюдений должно минимум в десять раз превосходить количество связей в сети.
Точного ответа на этот вопрос не существует. Сложность отображения, которое будет воспроизведено ИНС, сложно предсказать. К тому же нет линейной связи между количеством переменных и необходимых для этого наблюдений. Даже если входных данных будет немного, для обучения нейронной сети может понадобиться очень много примеров и шаблонов.
 Сбор данных для обучения нейронной сети
Сбор данных для обучения нейронной сети
В большинстве случаев речь идет о нескольких сотнях или тысячах наблюдений, но даже для самой элементарной задачи их не может быть меньше ста. Если у вас именно такая ситуация, можно смело говорить о недостаточном количестве данных для обучения ИНС, и для решения задачи лучше задействовать подходящую линейную модель.
Добавляем фото для обучения
Скачиваем уже собранный датасет с цветами, распаковываем его и копируем в папку tell-me → tf_files.
Адаптируем скрипты под актуальную версию tensorflow
На момент написания статьи актуальная версия tensorflow — 2.0. Но скрипты и алгоритмы, которые мы используем, заточены под старую версию, поэтому нужно применить немного магии автозамены:
- Переходим в каталог tell-me/scripts и находим файл retrain.py.
- Открываем его в любом редакторе кода, например Sublime Text 3.
- Нажимаем Ctrl + H или Command + H — включится режим поиска и автозамены текста.
- Первая строка (что заменить) → пишем tf. (с точкой).
- Вторая строка (на что заменить) → пишем tf.compat.v1. (тоже с точкой в конце).
- Нажимаем Replace All (Заменить всё).
- То же самое делаем в файле label-image.py.
- В том же файле label-image.py добавляем после строки 25 «import tensorflow as tf» такую строку:
tf.compat.v1.disable_eager_execution()
Благодаря этому колдунству мы заставим старый скрипт работать с новой библиотекой.
Обучаем нейросеть
- В командной строке командой cd переходим в папку tell-me (или в другую, если у вас проект называется по-другому).
- Запускаем команду:
Пошёл процесс обучения. В нём 4000 этапов, по времени занимает примерно 20 минут. За это время нейросеть обработает около 250 фото (это очень мало для нейросети) и научится отличать розу от ландышей:
Запускаем нейросеть
Чтобы проверить работу нашей нейросети, скачиваем любой файл с розой из интернета, кладём его в папку tell-me (или как у вас она называется) и пишем такую команду:
Нейросеть думает, а потом выдаёт ответ в виде процентов. В нашем случае она на 98% уверена, что это роза:
А вот как нейросеть реагирует на фото Цукерберга:
50% — что на фото тюльпан, и на 18% — что это одуванчик. А всё потому, что она умеет различать только 5 видов цветов, а не всяких там цукербергов.
Главная польза от машинного обучения
При умелом подходе, комбинируя различные виды машинного обучения, можно добиться автоматизации большинства рутинных бизнес-процессов. Иными словами, алгоритмы и роботы, подготовленные при помощи машинного обучения, могут выполнять всю рутинную работу. Людям же остается вся творческая часть: составление стратегий, ведение переговоров, заключение договоров и прочее. Это важный фактор, поскольку машина не может выйти за заданные ей рамки, а человеческий мозг способен мыслить нешаблонно.
Качественный анализ характеристик машинами подскажет, куда стоит направить больше усилий для привлечения клиентов, а задача людей – продумать стратегию для этих усилий. Хотите узнать, как лучше использовать машинное обучение и искусственный интеллект в целом для решения ваших бизнес-задач? Свяжитесь с нами, подскажем вариант, наиболее подходящий вашему бизнесу.
#Машинное обучение #Нейронные сети
11.01.2019
Используемые в статье картинки взяты из открытых источников и используются как иллюстрации.
Устанавливаем tensorflow
Tensorflow — открытая библиотека для машинного обучения и работы с нейросетями. Она будет отвечать за то, чтобы наш компьютер мог запустить нейросеть и правильно с ней работать.
Для установки пишем команду:
pip — это программа, которая отвечает в Python за скачивание, установку и обновление библиотек и вспомогательных пакетов. Это как магазин приложений Apple, только для командной строки и для разработчиков.
Чтобы убедиться, что библиотека установилась правильно и работает штатно, проверим её простым тестом.
1. Пишем команду:
2. Начало командной строки поменялось на >>> — это значит, питон готов к приёму своих команд. Пишем по очереди такое:
Если в ответ питон нам выдал что-то вроде ‘Hello, TensorFlow’, это значит, что мы всё сделали правильно.
История машинного обучения: от модели Байеса до искусственного интеллекта
1763
Теорема Байеса
В работе ‘An Essay towards solving a Problem in the Doctrine of Chances’, опубликованной через 2 года после смерти ее автора Томаса Байеса, было указано, что можно определить вероятность какого-либо события при условии, что произошло другое, статистически взаимозависимое, с ним событие. Байес предлагал формулу, по которой можно пересчитать вероятность, взяв в расчет как ранее известную информацию, так и данные новых наблюдений. Это считается первым появлением методов машинного обучения.
1943
Искусственный нейрон
Уоррен Мак-Каллок и Вальтер Питтс нарисовали линейную модель нейрона. Согласно их модели, нейроны упрощенно рассматриваются как устройство, оперирующее двоичными числами. Теоретически сеть из электронных нейронов могла выполнять числовые и логические операции.
1952
Первая самообучающаяся программа
Артур Сэмюэль создал самообучающуюся программу Checkers-playing, умевшую, как следует из ее названия, играть в шашки. В 1959 году он же ввел в научный обиход термин «машинное обучение» — процесс, в результате которого компьютеры способны показать поведение, которое в них не было явно запрограммировано.
1956
Появление термина «искусственный интеллект»
Летняя конференция в Дартмутском колледже стала местом втречи людей, интересующихся моделированием человеческого разума, утвердила появление новой области науки и дала ей название: Artificial Intelligence (искусственный интеллект). Первым это словосочетание произнес организатор конференции — преподаватель математики Джон Маккарти.
1957
Перцептрон — первый нейрокомпьютер
Ученый Фрэнк Розенблатт предложил первую компьютерную модель восприятия информации мозгом. Спустя 3 года в Корнеллском университете он построил систему Mark I Perceptron, которую можно назвать первым нейрокомпьютером. С помощью фотоэлементов Mark I мог распознавать буквы, отпечатанные на карточках. Тем самым Фрэнк Розенблатт на практике реализовал модель Мак-Каллока–Питтса.
1959
Универсальный решатель задач
Ученые Герберт Саймон, Аллен Ньюэлл и Клиффорд Шоу разработали компьютерную программу — универсальную машину для решения задач. Принято считать, что это одна из первых компьютерных программ, обладающих искусственным интеллектом. Она могла решать задачу, не зная заранее способа решения.
1966
Первый виртуальный собеседник
Джозеф Вейцбаум написал виртуального собеседника ELIZA, способного имитировать (скорее пародировать) диалог с психотерапевтом. Своим названием программа обязана главной героине пьесы Бернарда Шоу «Пигмалион».
1976–1982
Самообучающаяся система «Эвриско»
«Эвриско» — компьютерная программа, написанная Дугласом Ленатом. Она состояла из эвристик, т.е. логических правил «если… то», по которым идет рассуждение. Это была экспертная система со средствами самообучения, способная учиться и уточнять уже созданные эвристики. Предшественником «Эвриско» была программа «Автоматический математик».
1985
Первая нейросеть
Терри Сейновски создает искусственную нейронную сеть NetTalk. В ее задачи входило изучение произношения английских букв в слове в зависимости от контекста — соседних букв. Программа для машинного чтения текста стала первым широко известным приложением, которое работало с искусственными нейросетями.
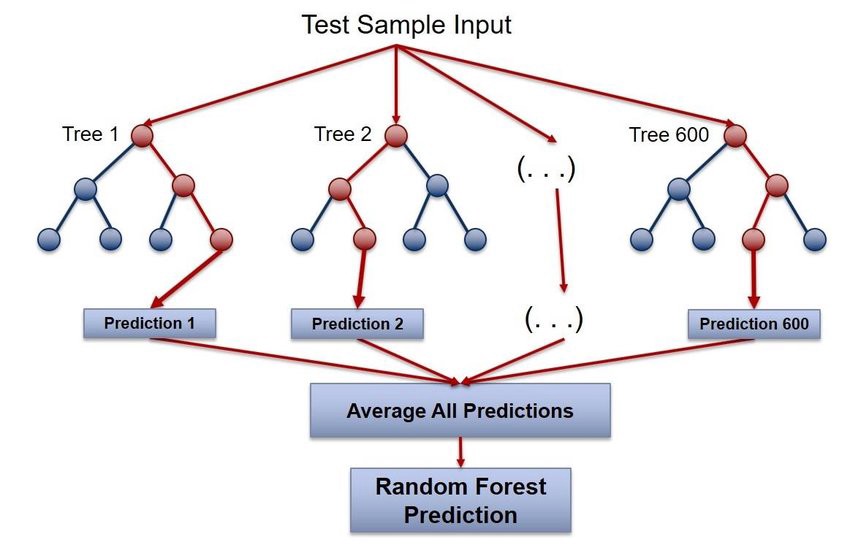
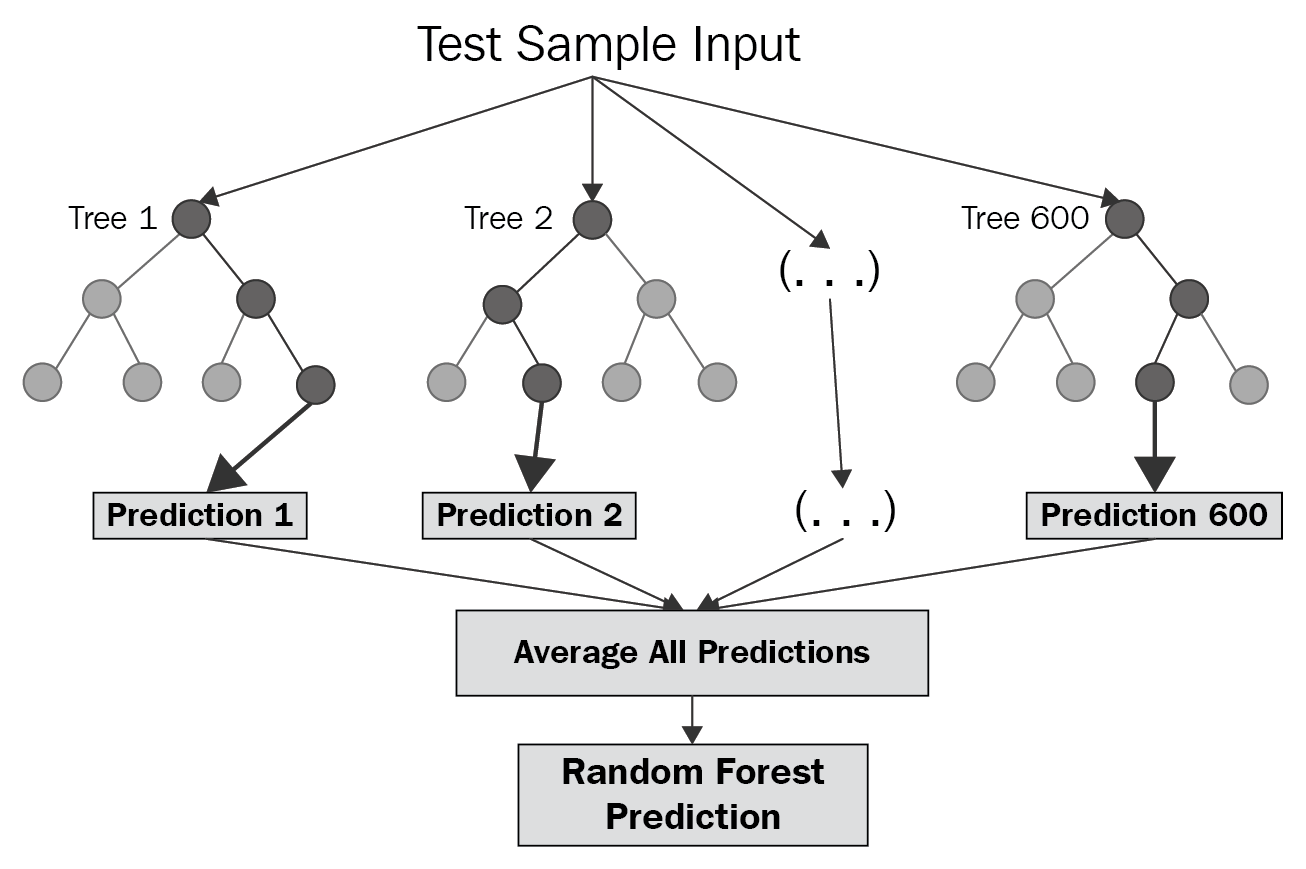

1997
Машина победила в шахматном турнире
11 мая 1997 года суперкомпьютер Deep Blue, разработанный компанией IBM, выиграл матч из 6 партий у чемпиона мира по шахматам Гарри Каспарова.
2004
Упрощение обработки Больших данных
Благодаря увеличению мощностей компьютеров и накопленным Большим данным «зима искусственного интеллекта» закончилась. Знаковым событием стал 2004 год, когда компания Google раскрыла свою технологию MapReduce. Два года спустя появился ее открытый аналог Hadoop, который дал возможность распределить обработку огромных объемов данных между простыми процессорами. Следующим шагом стал программный каркас Apache Spark, необходимый для распределенной обработки неструктурированных и слабоструктурированных данных.
2016
Машина победила в го
27 января программа AlphaGo, разработанная компанией DeepMind (одной из дочерних компаний Google), выиграла 5 игр подряд у профессионального игрока в го. Чемпион Европы Фань Хуэй после тех игр сказал: «Если бы меня заранее не предупредили, я бы решил, что против меня играет немного странный, но очень сильный живой игрок». Число допустимых комбинаций в го больше, чем атомов во Вселенной, поэтому считалось, что компьютер не способен играть на равных с профессиональным игроком из-за невозможности перебора всех доступных вариантов развития событий.
2017
Russian Artificial Intelligence Forum
Помогают ли нейронные сети улучшить показатели производства?
О.Рэлли провел исследование, чтобы выяснить, помогают ли нейронные сети улучшить показатели производства. И попросил сотрудников различных предприятий указать, на сколько процентов улучшились показатели работы, и объяснить, какие программы использовались при этом. Получилась следующая картина:
– Компьютерное «зрение» – 13 проц.
– Интеллектуальный анализ текста – 11 проц.
– Анализ информации – 9 проц.
– Финансы – 3 проц.
– Прогнозы – 3 проц.
– Здравоохранение – 2 проц.
– Речевые технологии – 2 проц..
Неудивительно, что алгоритмы нейронных сетей привлекли внимание разнообразными функциями, обеспечивающими как машинный перевод, так и работу беспилотных автомобилей. Предприятия начинают использовать нейронные сети для того, чтобы обнаружить мошенников, оптимизировать промышленную работу, заниматься техническим обслуживанием и ремонтом, составлять рекомендации для поисковых систем
Становится ясно, что нейронные сети способны полностью перестроить процессы в ведущих индустриях. Главными игроками в последующие годы станут те предприятия, которые будут использовать нейронные сети, а те, кто не сочтет нужным работать с ними, проиграет. По крайней мере, так считают Терадата и О. Рэлви.
Одна из главных проблем, возникающих при работе с глубоким обучением – это интенсивность моделей, ведь их запуск требует специальных ресурсов аппаратного и программного обеспечения. На данный момент лучшим решением для обучения компьютерных систем является графический процессор, разработанный в игровой индустрии и подходящий для параллельных вычислений, принятых в глубоком обучении.
Кроме того, нейронные сети периодически кажутся непонятными. Они используют скрытые слои, которые помещают в секретное место информацию, обработанную машиной для принятия решения. В некоторой степени, их работу невозможно понять полностью, и рядовому сотруднику приходится полагаться на тот выбор, который совершают нейронные сети. Тем не менее, в некоторых индустриях такая вариативность является неприемлемой. Например, в Европе по закону о защите персональных данных, любое финансовое предприятие обязано объяснить, как используются данные, переданные в компанию ее целевой аудиторией. В противном случае, использование информации и передача ее третьим лицам является незаконной.
Конечно, чтобы избежать проблем с законом, многие предприятия пользуются системами, помогающими устранить такую вариативность. Один из известнейших методов был разработан в Университете Вашингтона – и носит название «Локальные интерпретируемые модельно-агностические объяснения» (LIME). Эта модель позволяет вычислить алгоритм в момент принятия решения и предложить информацию, которую сможет прочитать человек. В случае если имело место мошенничество, знание данных сведений обеспечит безопасность предприятия, так как его руководство легко поймет, почему случилась утечка информации или была зафиксирована финансовая кража.
Типы задач, которые решают нейронные сети
Выделяют несколько базовых типов задач, для решения которых могут использоваться нейросети.
- Классификация. Для распознавания лиц, эмоций, типов объектов: например, квадратов, кругов, треугольников. Также для распознавания образов, то есть выбора конкретного объекта из предложенного множества: например, выбор квадрата среди треугольников.
- Регрессия. Для определения возраста по фотографии, составления прогноза биржевых курсов, оценки стоимости имущества и других задач, требующих получения в результате обработки конкретного числа.
- Прогнозирования временных рядов. Для составления долгосрочных прогнозов на основе динамического временного ряда значений. Например, нейросети применяются для предсказания цен, физических явлений, объема потребления и других показателей. По сути, даже работу автопилота Tesla можно отнести к процессу прогнозирования временных рядов.
- Кластеризация. Для изучения и сортировки большого объема неразмеченных данных в условиях, когда неизвестно количество классов на выходе, то есть для объединения данных по признакам. Например, кластеризация применяется для выявления классов картинок и сегментации клиентов.
- Генерация. Для автоматизированного создания контента или его трансформации. Генерация с помощью нейросетей применяется для создания уникальных текстов, аудиофайлов, видео, раскрашивания черно-белых фильмов и даже изменения окружающей среды на фото.
Реклама в сетях
Часто клиенты скептически относятся к предложению запустить рекламу в сетях Яндекса и Google. Обосновывают это тем, что им как пользователям рекламные блоки на сайтах ох как надоели. Зачем, мол, тратить деньги на рекламу, на которую «никто не кликает»?
На это мы обычно отвечаем, что у рекламы в сетях сейчас настолько гибкие возможности и при грамотной настройке можно найти и заинтересовать своим предложением ЦА и вполне себе остаться в рамках бюджета.
Если бюджет очень ограничен, то рекомендуем сосредоточиться на ретаргетинге в сетях. Для него собираем аудиторию, которая уже есть у сайта, сегментируем по микро- и макроконверсиям и запускам для персонализированные рекламные сообщения.
Что отнести к микроконверсиям:
-
посещение определенной страницы сайта, например, посещение страницы с контактами или страницы с прайсом;
-
подписка на рассылку;
-
регистрация на сайте;
-
добавление товара в корзину и т. д.
Что отнести к макроконверсиям:
-
оформленный заказ;
-
отправленная форма обратной связи;
-
клик по кнопке «Позвонить» и другие.
Таким образом, мы убьем сразу двух зайцев — проанализируем поведение посетителей сайт и «дожмем» аудиторию, которая уже знакома с нами.
Теория
Биологи до сих пор не знают, как именно работает мозг, но принцип действия отдельных элементов нервной системы неплохо изучен. Она состоит из нейронов — специализированных клеток, которые обмениваются между собой электрохимическими сигналами. У каждого нейрона имеется множество дендритов и один аксон. Дендриты можно сравнить со входами, через которые в нейрон поступают данные, аксон же служит его выходом. Соединения между дендритами и аксонами называют синапсами. Они не только передают сигналы, но и могут менять их амплитуду и частоту.
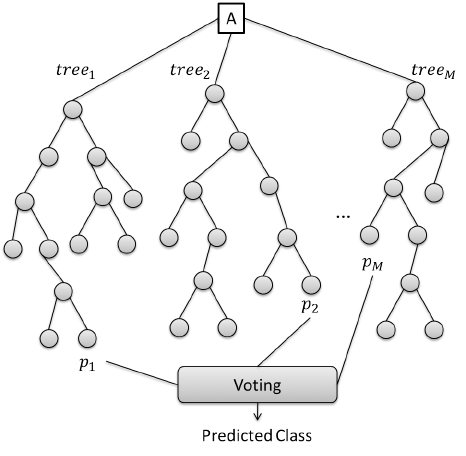
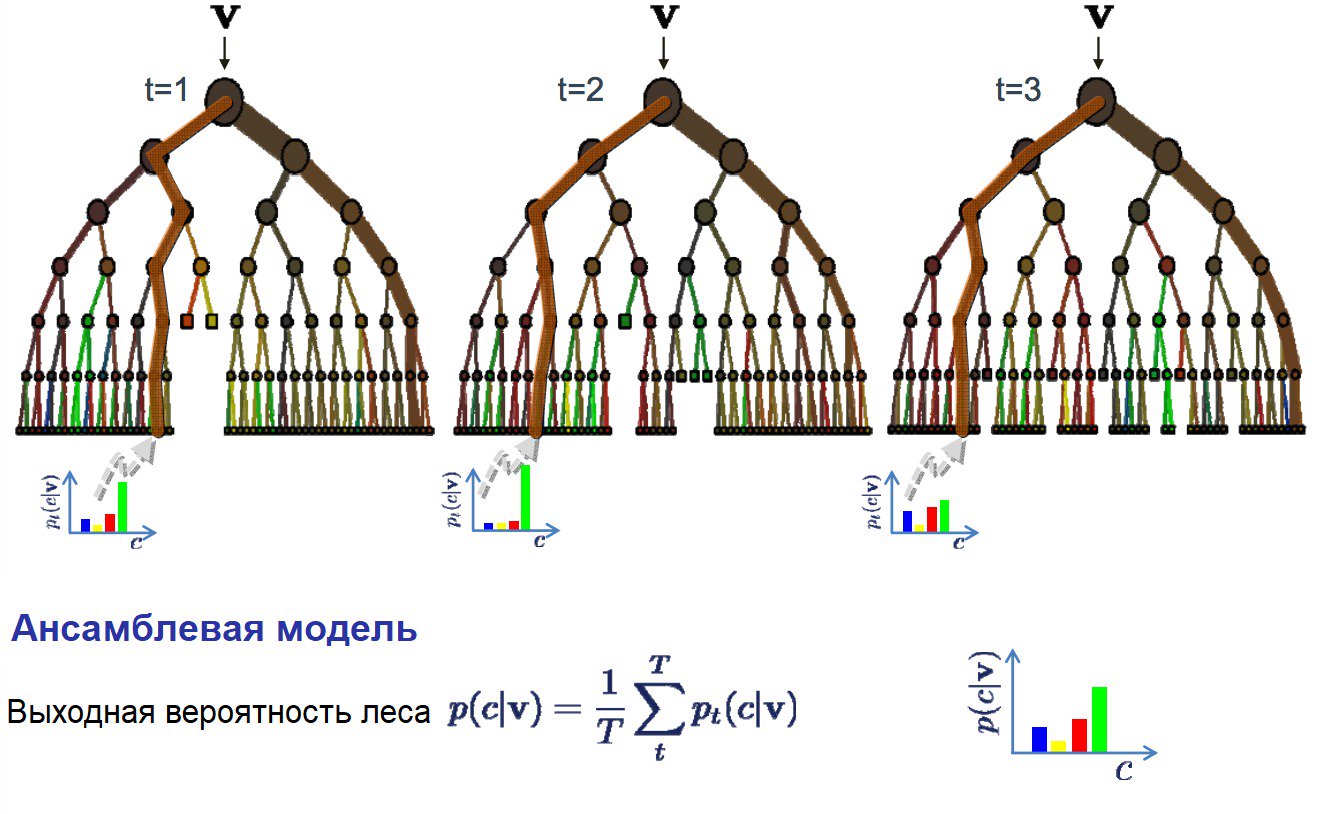
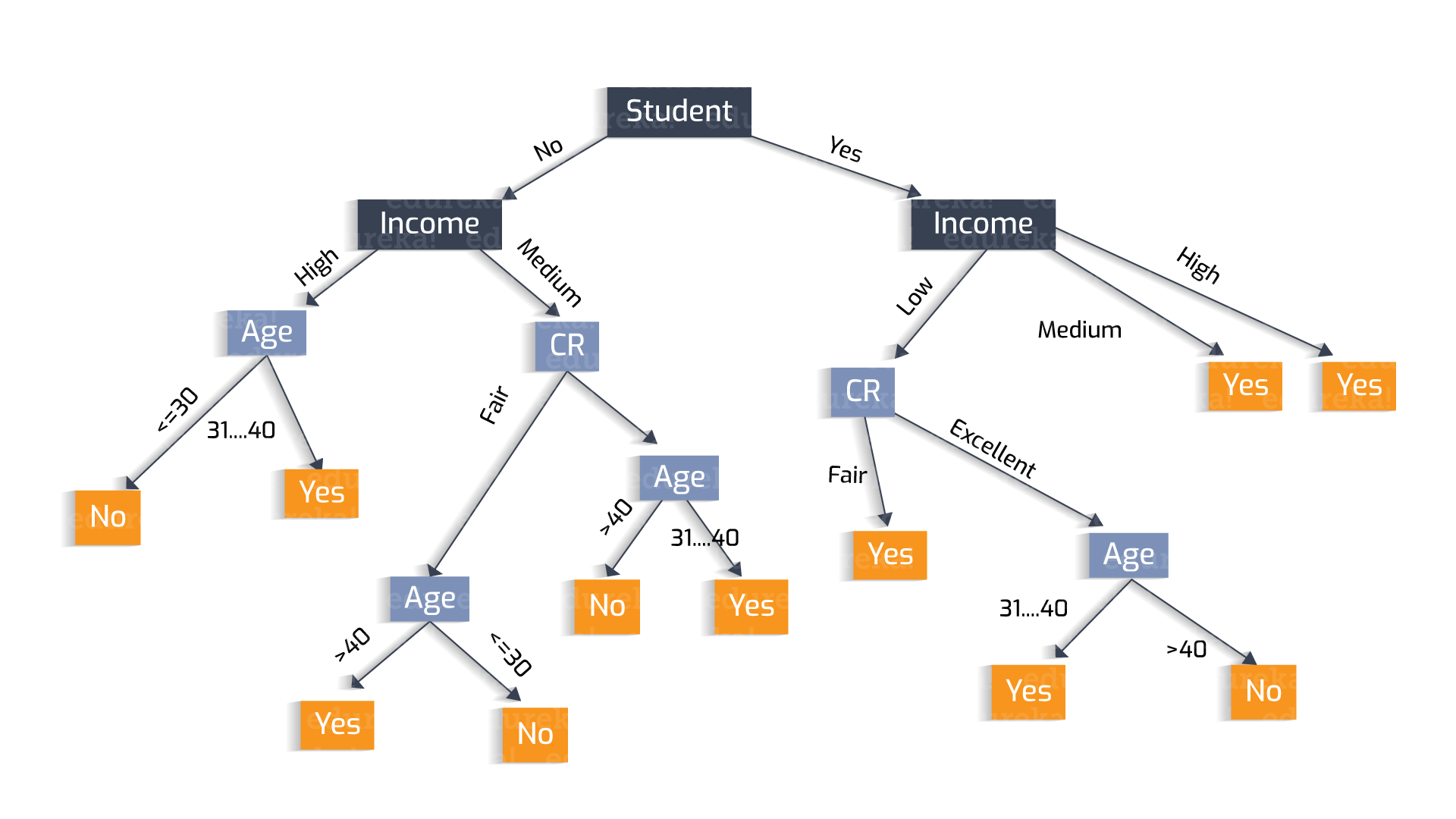
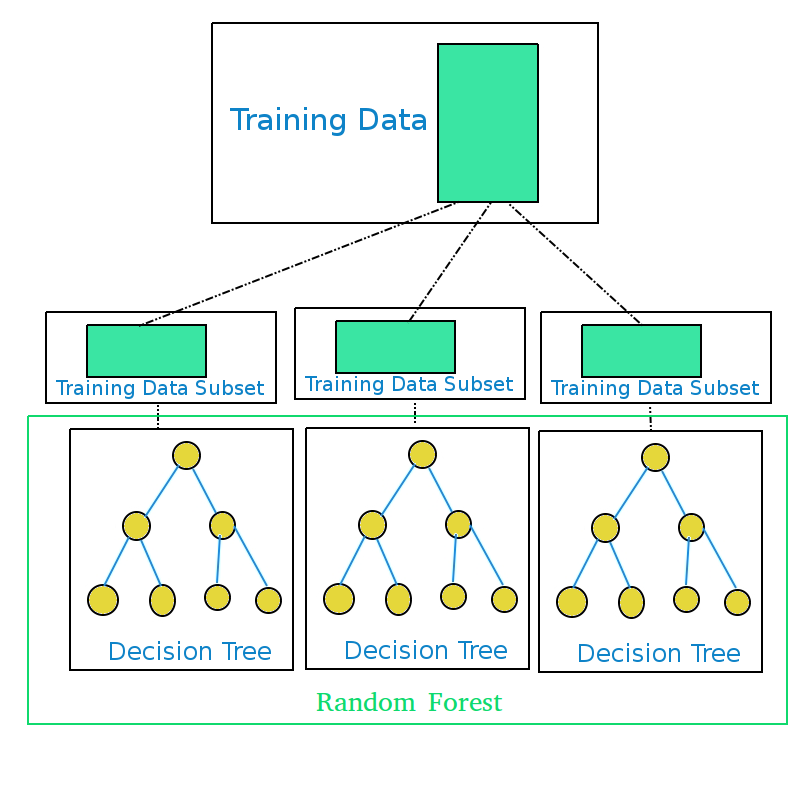
Преобразования, которые происходят на уровне отдельных нейронов, очень просты, однако даже совсем небольшие нейронные сети способны на многое. Все многообразие поведения червя Caenorhabditis elegans — движение, поиск пищи, различные реакции на внешние раздражители и многое другое — закодировано всего в трех сотнях нейронов. И ладно черви! Даже муравьям хватает 250 тысяч нейронов, а то, что они делают, машинам определенно не под силу.
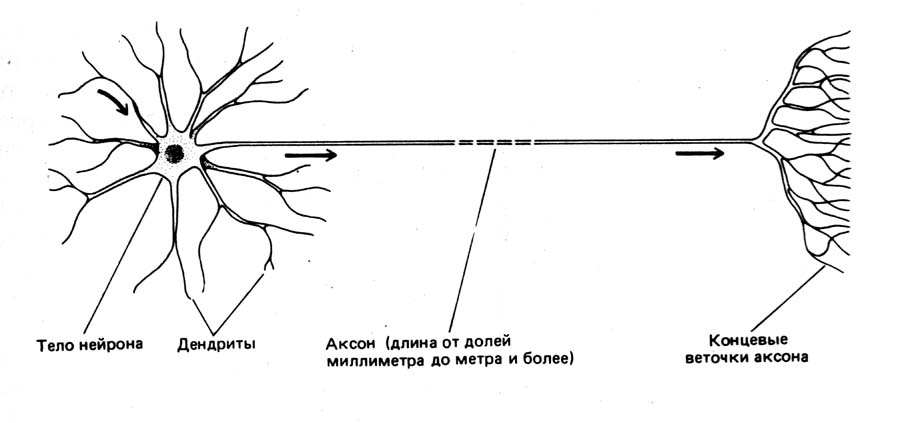
Почти шестьдесят лет назад американский исследователь Фрэнк Розенблатт попытался создать компьютерную систему, устроенную по образу и подобию мозга, однако возможности его творения были крайне ограниченными. Интерес к нейросетям с тех пор вспыхивал неоднократно, однако раз за разом выяснялось, что вычислительной мощности не хватает на сколько-нибудь продвинутые нейросети. За последнее десятилетие в этом плане многое изменилось.
Электромеханический мозг с моторчиком

Машина Розенблатта называлась Mark I Perceptron. Она предназначалась для распознавания изображений — задачи, с которой компьютеры до сих пор справляются так себе. Mark I был снабжен подобием сетчатки глаза: квадратной матрицей из 400 фотоэлементов, двадцать по вертикали и двадцать по горизонтали. Фотоэлементы в случайном порядке подключались к электронным моделям нейронов, а они, в свою очередь, к восьми выходам. В качестве синапсов, соединяющих электронные нейроны, фотоэлементы и выходы, Розенблатт использовал потенциометры. При обучении перцептрона 512 шаговых двигателей автоматически вращали ручки потенциометров, регулируя напряжение на нейронах в зависимости от точности результата на выходе.
Вот в двух словах, как работает нейросеть. Искусственный нейрон, как и настоящий, имеет несколько входов и один выход. У каждого входа есть весовой коэффициент. Меняя эти коэффициенты, мы можем обучать нейронную сеть. Зависимость сигнала на выходе от сигналов на входе определяет так называемая функция активации.
В перцептроне Розенблатта функция активации складывала вес всех входов, на которые поступила логическая единица, а затем сравнивала результат с пороговым значением. Ее минус заключался в том, что незначительное изменение одного из весовых коэффициентов при таком подходе способно оказать несоразмерно большое влияние на результат. Это затрудняет обучение.
В современных нейронных сетях обычно используют нелинейные функции активации, например сигмоиду. К тому же у старых нейросетей было слишком мало слоев. Сейчас между входом и выходом обычно располагают один или несколько скрытых слоев нейронов. Именно там происходит все самое интересное.
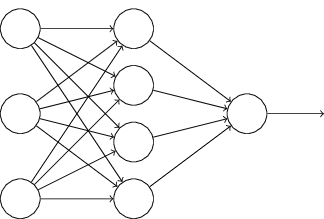
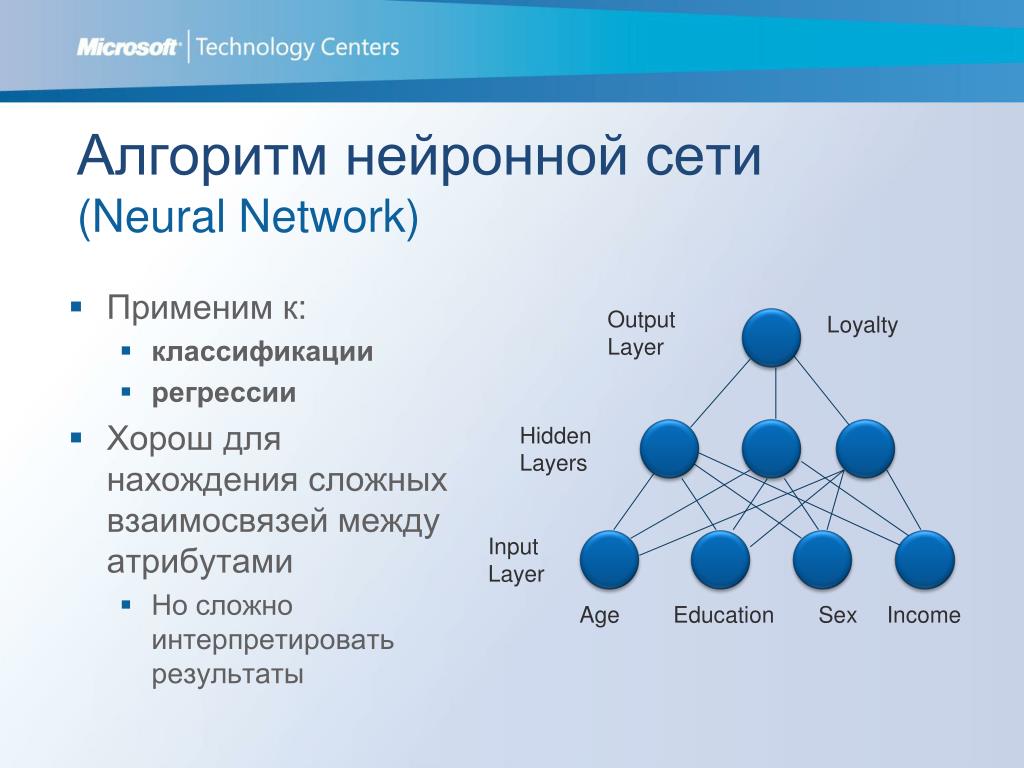
Чтобы было проще понять, о чем идет речь, посмотри на эту схему. Это нейронная сеть прямого распространения с одним скрытым слоем. Каждый кружок соответствует нейрону. Слева находятся нейроны входного слоя. Справа — нейрон выходного слоя. В середине располагается скрытый слой с четырьмя нейронами. Выходы всех нейронов входного слоя подключены к каждому нейрону первого скрытого слоя. В свою очередь, входы нейрона выходного слоя связаны со всеми выходами нейронов скрытого слоя.
Не все нейронные сети устроены именно так. Например, существуют (хотя и менее распространены) сети, у которых сигнал с нейронов подается не только на следующий слой, как у сети прямого распространения с нашей схемы, но и в обратном направлении. Такие сети называются рекуррентными. Полностью соединенные слои — это тоже лишь один из вариантов, и одной из альтернатив мы даже коснемся.
Банковская сфера
В самой консервативной из перечисленных здесь отраслей реализовали кейс, напоминающий фантастический фильм «Особое мнение». Мы приведем только один достаточно узкий кейс, но на его примере можно понять, какие широкие возможности предоставляет машинное обучение на поле борьбы с мошенничеством в банках.
Компания «Инфосистемы Джет» разработала для Сбербанка модель, которая детектирует поведение работников банка, и, если оно становится аномальным, сигнализирует службе безопасности банка. В качестве одного из примеров приведем следующий кейс. В банках есть определенное количество «спящих счетов». Открывшие их люди по разным причинам не обращались больше в банк. По данным ЦБ, таких вкладов около 3%. И если подделать карту и вывести деньги с такого счета, никто не заметит. Если машина выявляет какую-то аномалию в поведении сотрудника, его не увольняют, но за его работой начинают наблюдать пристальнее. Если несколько дней подряд кто-то проверяет счета, а затем выдаются карты, привязанные к счетам, по которым долгое время не происходило никаких движений, офицер безопасности может заподозрить мошенничество со стороны сотрудника банка и потребовать проведения более тщательной служебной проверки.
Не будем перечислять все направления, в которых машинное обучение может помочь банковскому бизнесу, просто назовем 8 самых интересных.
- Next-best-action для увеличения ARPU. Прогнозирование следующей оптимальной активности с существующим клиентом. Позволяет увеличить конверсию продаж услуг и продуктов, что увеличивает показатели ARPU и LTV.
- Лучшее маркетинговое предложение. Выбор оптимальной целевой группы для коммуникации в рамках маркетинговой программы. За счет оптимального подбора людей, для которых это предложение сейчас актуально, растет конверсия в продажи.
- Прогноз оптимальных тарифов. Подбор характеристик тарифов для оптимизации уровня конверсии. Позволяет подбирать оптимальные характеристики тарифов для выбранных групп существующих клиентов, что увеличивает конверсию продаж.
- Прогноз досрочного закрытия депозита. Прогнозирование в заданном промежутке времени досрочного закрытия депозита клиентом. Позволяет принять ряд мер для снижения этой вероятности, а также оценить вероятность снижения объема основных средств.
- Кредитный скоринг заявок. Скоринг поступающих заявок на кредит на базе существующей популяции клиентов и макроэкономических событий как для физических, так и для юридических лиц. Позволяет снизить риски просрочек и невозвратов.
- Прогноз возникновения просрочки по действующим кредитным договорам. Позволяет оценивать риски, связанные с необходимостью частичного или полного залогового покрытия просроченных платежей.
- Прогноз стоимости основных активов. Прогноз стоимости составных частей (ценные бумаги, недвижимость) основных активов на заданный промежуток времени. Позволяет точнее оценивать риски, связанные с объемом основных активов и целесообразностью их покупки или продажи.
- Контроль исполнения скриптов операторами. Помогает определять операторов, которые могли что-то предложить, но решили этого не делать и быстро закончили разговор.
Неглубокие (shallow) нейронные сети
Неглубокие модели, как и глубокие нейронные сети, тоже популярные и полезные инструменты. Например, word2vec — группа неглубоких двухслойных моделей, которая используется для создания векторных представлений слов (word embeddings). Представленная в Efficient Estimation of Word Representations in Vector Space, word2vec принимает на входе большой корпус текста и создает векторное пространство. Каждому слову в этом корпусе приписывается соответствующий вектор в этом пространстве. Отличительное свойство — слова из общих текстов в корпусе расположены близко друг к другу в векторном пространстве.
В статье описаны архитектуры нейронных сетей: глубокий многослойный перцептрон, сверточная, рекурсивная, рекуррентная сети, нейросети долгой краткосрочной памяти, sequence-to-sequence модели и неглубокие (shallow) сети, word2vec для векторных представлений слов. Кроме того, было показано, как функционируют эти сети, и как различные модели справляются с задачами обработки естественного языка. Также отмечено, что сверточные нейронные сети в основном используются для задач классификации текста, в то время как рекуррентные сети хорошо работают с воспроизведением естественного языка или машинным переводом. В следующих части серии будут описаны существующие инструменты и библиотеки для реализации описанных типов нейросетей.
Интересные статьи:
- Facebook создали алгоритм для перевода с редких языков
- NLP Architect от Intel: open source библиотека моделей обработки естественного языка
- Как создать чат-бота с нуля на Python: подробная инструкция



