
Что такое машинное обучение
На данный момент не существует общепринятого определения понятия «машинное обучение» (machine learning, ML). Хотя в большинстве случаев данный термин определяется специалистами вполне конкретно.
Машинное обучение представляет собой научную дисциплину, главная задача которой — научить искусственный интеллект на основе предоставляемой ему информации об окружающем мире самостоятельно принимать решения, самообучаться и постоянно совершенствоваться в своем самообучении.
Крупные представители мировой IT-индустрии, а также именитые исследовательские компании так трактуют суть ML:
- «Практическое использование алгоритмов для анализа данных, изучения их и последующего прогнозирования какого-либо явления» (NVIDIA).
- «Наука о том, как научить компьютеры функционировать без явного программирования» (Стэндфортский университет).
- «Технология, основанная на алгоритмах, способных учиться на заложенных данных без помощи средств программирования» (McKinsey & Co).
- «Алгоритмы, способные самостоятельно выбирать метод решения важных задач путем обобщения заложенных в систему примеров» (Вашингтонский университет).
- «Сфера деятельности, функция которой состоит в поиске способов создания компьютерных систем, способных самообучаться и самостоятельно улучшаться по мере накопления опыта, а также в поиске фундаментальных закономерностей, по которым работают все процессы обучения» (Университет Карнеги Меллон).
 Что такое машинное обучение
Что такое машинное обучение
В целом можно сказать про машинное обучение, что это часть науки об искусственном интеллекте, а нейронные сети являются в свою очередь одной из разновидностей ML.
Банки используют Machine Learning: 9 успешных примеров внедрения технологий за рубежом и в России
Machine Learning (машинное обучение) и банки: как финансовые корпорации всего мира делают большие деньги на анализе больших данных с помощью методов искусственного интеллекта.
Машинное обучение в зарубежных кредитных организациях
- Американский банк JPMorganChase разработал автоматизированную модель машинного обучения для анализа документов и агрегации важных данных из них, что позволило обработать 12 тысяч кредитных договоров за несколько секунд, хотя раньше это занимало около 360 тысяч человеко-часов .
- Открытие полностью автоматизированных кредитных отделений в другом американском банке, Bank of America, позволило в несколько раз сократить затраты на содержание новых офисов. Их площадь в 4 раза меньше обычного, а вместо сотрудников – интеллектуальные банкоматы и экраны для удаленной видеосвязи с работниками других филиалов .
- Еще один известный банк в США, Goldman Sachs, сократил расходы на заработную плату трейдеров в 300 раз, оставив вместо 600 сотрудников только 2 и автоматизировав процессы покупки и продажи акций. Также эта финансовая корпорация успешно внедрила программное обеспечение для автоматического объединения балансов кредитных карт .
- Система на основе искусственного интеллекта, используемая китайской компанией по сбору долгов Ziyitong показывает 2-кратное возрастание коэффициента возмещения кредитов, просроченных на срок до 1-ой недели: 41% вместо 20%. Этот результат достигнут за счет сбора и анализа данных о заемщиках и их друзьях и последующего разговора диалогового робота с должником по телефону. Разговор автоматически записывается и анализируется, определяется формулировка, которая с наибольшей вероятностью воздействует на заемщика и заставит вернуть долг. Кроме того, система связывается с друзьями должника и просит вернуть его деньги через знакомых .

Как банки используют большие данные и машинное обучение
Машинное обучение в российских банках
Здесь мы уже подробно писали, как методы искусственного интеллекта, машинного обучения и анализа больших данных помогли Сбербанку за год заработать около $3-х миллиардов. Однако, это не единственный пример успешного применения современных информационных технологий в отечественном финансовом секторе. Другие кредитные организации также демонстрируют отличные результаты в этом направлении, в частности:
- в 2 раза ускорена работа контакт-центра в банке «Открытие» ;
- в 3 раза сокращено максимальное время, необходимое для принятия решения по кредиту в Бинбанке ;
- в 1,5 раза снижены расходы на инкассацию в банке «Хлынов» ;
- внедрение в Тинькофф-банке системы противодействия легализации доходов, полученных преступным путем и финансированию терроризма, повысило обнаружение подозрительных операций на 95% и снизило количество ложных срабатываний на 50%. Это достигнуто за счет алгоритмов машинного обучения, автоматизации создания и подготовки отчётов, рассылки уведомлений, отсечения заведомо правильных счетов и транзакций из исследуемой выборки. В результате банк перераспределил ресурсы с обязательного контроля на непосредственное расследование криминальных схем .

Big Data и Machine Learning в финансовой сфере
Эти примеры показывают глобальный тренд на тотальную автоматизацию банковской деятельности и повсеместное внедрение инструментов Big Data и Machine Learning во все сферы финансового сектора. Чтобы через пару лет робот не занял ваше рабочее место, двигайтесь вместе с новыми технологиями – станьте профессионалом в сфере анализа больших данных и машинного обучения! Для этого приходите на наши практические курсы для инженеров, финансистов и руководителей, где на конкретных примерах мы учимся выбирать, настраивать и администрировать методы и средства работы с Big Data и Machine Learning. Подробную информацию об обучении смотрите здесь. До встречи на занятиях!
Источники
- https://blog.liga.net/user/vfedak/article/5-primerov-primeneniya-mashinnogo-obucheniya-veduschimi-bankami-ssha
- https://incrussia.ru/fly/kompanii-zamenyayut-lyudey-mashinami-eto-tendentsiya/
- http://www.tadviser.ru/index.php/Статья:Искусственный_интеллект_в_банках
- https://www.bigdataschool.ru/bigdata/искусственный-интеллект-и-сбербанк.html
- https://rb.ru/news/finmachine/
- https://secretmag.ru/opinions/kak-neiroseti-boryutsya-s-otmyvaniem-deneg.htm
Актуальные проблемы российского рынка
Более активному развитию машинного обучения на территории нашего государства препятствует не только недостаток практического опыта, о котором мы упоминали выше. Ряд крупных компаний уже давно осознал значимость и практическую результативность применения технологий искусственного интеллекта, но определенные барьеры не позволяют организациям достигать желаемых темпов роста и развития.
Одним из основных ограничивающих факторов является отсутствие ИТ-инфраструктуры, которая позволяла бы интегрировать машинное обучение в бизнес-процессы компании. Для корректной работы технологий искусственного интеллекта необходимо соответствующее программное и аппаратное обеспечение, направленное в первую очередь на распределенную обработку и анализ больших массивов данных. На практике подобных готовых инфраструктур в отечественных компаниях нет, и их приходится выстраивать практически с нуля, попутно перенося существующие бизнес-процессы в новую экосистему.
Кроме этого, остро ощущается нехватка квалифицированных кадров, с помощью которых можно не только разработать прорывной алгоритм машинного обучения, но и успешно интегрировать его в существующие сложные бизнес-процессы компании. На практике большинство стартапов, конференций и хакатонов в России направлены на обсуждение и решение бизнес-задач «в вакууме». При попытке интеграции полученного алгоритма в реальные условия компания сталкивается с отсутствием инженеров, способных сделать это.
Решение предыдущей проблемы порождает новую — нехватка бюджетов на дорогостоящее прикладное программное обеспечение и на высокооплачиваемые вакансии профильных специалистов. Компании пока что не готовы меняться так быстро; следовательно, согласование бюджетов на модернизацию ИТ-инфраструктур, введение новых ставок сотрудников и прочие сопутствующие расходные операции протекают сложно и неохотно. Для оптимизации необходимы понимающие эти процессы и современный рынок ИИ люди, которыми руководит ответственный за это направление директор по данным (Chief Data Officer).
Create ML
И вот в этом году Apple, помимо Core ML 2, наконец показала собственный инструмент для обучения моделей — фреймворк Create ML, использующий нативные технологии Apple — Xcode и Swift.
Он работает быстро, а создание типовых моделей с помощью Create ML становится по-настоящему простым.
На WWDC были озвучены впечатляющие показатели Create ML и Core ML 2 на примере приложения Memrise. Если раньше на обучение одной модели с использованием 20 тысяч изображений требовалось 24 часа, то Create ML сокращает это время до 48 минут на MacBook Pro и до 18 минут — на iMac Pro. Размер обученной модели уменьшился с 90MB до 3MB.
Create ML позволяет использовать в качестве исходных данных изображения, тексты и структурированные объекты — например, таблицы.
Тайны черного ящика
Я не могу переоценить это: черный ящик. Является. Жесткий. Стоит также отметить, что обзор этой игры без каких-либо спойлеров практически невозможен, так что будьте готовы к нескольким ответам о том, как решить некоторые уровни.
Blackbox работает, предоставляя чрезвычайно тонкие подсказки на каждом уровне для того, что вам нужно сделать. Вы должны действительно мыслить нестандартно и быть умным, потому что намеки трудны. На каждом уровне есть как минимум один пустой квадрат. Квадрат загорается, когда вы выясняете, какую задачу вы должны выполнить с помощью оборудования, и завершите ее.
У каждого уровня есть такая простая цель: осветить квадрат, но иногда для этого требуются часы, если не дни.
Когда вы только начинаете, это немного сложнее. Вы начинаете первый уровень и замечаете, что на экране есть визуальный индикатор, который, кажется, перемещается в соответствии с тем, как вы перемещаете свой телефон. Итак, вы переворачиваете свой телефон и вуаля, один из квадратов загорается. Если вы похожи на меня, вы сделали это и подумали: «Ух ты, я все-таки могу неплохо мыслить нестандартно».






Blackbox смирит вас очень быстро. Как только вы достигнете третьего и четвертого уровня, вам будет сложно понять, что в мире вы должны делать. Это может быть буквально что угодно, кроме взаимодействия с экраном. Столько раз я постучал по экрану в отчаянной надежде, что описание игры соврал. Пока что нет.


Не думайте, что вы можете открыть все уровни и сразу же сделать их. У каждого есть квадрат, который стреляет из него в зависимости от времени суток. Чтобы зажечь, он должен стрелять лучом каждый час на часах. Это означает, что вам нужно открывать этот уровень каждый час в течение 12 часов, чтобы окончательно решить его.
Некоторые уровни не имеют абсолютно никаких визуальных индикаторов, или они настолько малы, что потребуется целая вечность, чтобы связать это с соответствующей задачей. Вам просто нужно быть креативным.
Однако есть небольшая надежда, потому что чем больше вы играете, тем больше вы можете заработать более очевидных подсказок. Подсказки читаются как загадки, которые должны быть чуть менее тонкими, чем на экране, но все же загадочными. Если вы действительно изо всех сил пытаетесь заработать кредитные подсказки, вы можете приобрести их в приложении, начиная с 0, 99 долл. США за одно, вплоть до 19, 99 долл. США за 42.
Практическое применение ML-технологий
Машинное обучение уже применяется во всех сферах деятельности человека. Еще в 2017 году под управлением Стэнфордского университета был запущен новый индекс AI100 для отслеживания динамики в сфере ИИ. Согласно данным, полученным университетом, количество стартапов с 2000 по 2018 год выросло в 14 раз. Рассмотрим, в каких областях нас ждут технологические прорывы благодаря ML.
Робототехника
В будущем роботы станут самообучаться ранее поставленным перед ними задачам. К примеру, смогут работать над добычей полезных ископаемых — нефти, газа и других. Они смогут, например, изучать морские глубины, тушить пожары. Программисты могут самостоятельно не писать массивные и сложные программы, опасаясь допустить ошибку в коде. ИИ повлияет и на повышение качества частной жизни человека: у нас уже есть беспилотные автомобили, роботы-пылесосы, трекеры сна, физической активности и здоровья и прочие продукты интернета поведения.
Маркетинг
Самый наглядный пример использования машинного обучения в маркетинге — поисковые системы Google и Яндекс, которые с его помощью контролируют релевантность рекламных объявлений.Социальные сети FaceBook, ВКонтакте, Instagram и другие применяют собственные аналитические машины для исследования интересов пользователей и совершенствования персонализации новостной ленты.Маркетинговые исследования, предваряющие разработку и релиз продуктов компании, станут проще с точки зрения реализации, а итоговые данные будут более точными. Выделение кластеров в группах со схожими параметрами превратит кастомизированные предложения в реальность — можно будет решать задачи не групп потребителей, а каждого в отдельности.
Безопасность
Современную сферу обеспечения безопасности невозможно представить без машинного обучения. Системы распознавания лиц в метро и использование камер, сканирующих лица и номера машин при движении по автодорогам, стали неотъемлемой частью человеческой жизни и незаменимыми помощниками для полиции в поиске преступников и потерявшихся людей.
Финансовый сектор и страхование
Более точные биржевые прогнозы и оценка капитализации брендов, решения о выдаче кредитных продуктов частным лицам и предприятиям, определение стоимости и целесообразности страховки и даже снижение очередей в офисах при параллельном сокращении издержек на персонал — только часть возможностей, которые станут доступны в этой сфере.
Общественное питание
На основе Big Data разрабатываются специальные предложения для гостей с учетом загрузки посадочных мест в ресторанах и кафе, функционируют сервисы по планированию закупок для поваров.
Примечание Воронежская пивоварня Brewlok и разработчики из NewShift решили
использовать возможности Big Data для разработки
рецепта идеального пива.
На протяжении месяца они собирали отзывы и выделяли критерии оценки
вкуса, аромата и цвета. На основе полученных данных из почти двух с
половиной тысяч отзывов аналитики сформулировали описание «идеального
пива», которое легло в основу рецепта.
Медицина
В медицинских учреждениях машинное обучение позволяет быстро обрабатывать данные пациента, производить предварительную диагностику и подобрать индивидуальное лечение, опираясь на сведения о заболеваниях пациента из базы данных. ML также позволяет автоматически выделять группы риска при появлении новых штаммов вирусных заболеваний.
Добыча полезных ископаемых
Анализ почвы доказывает или опровергает наличие полезных ископаемых, помогает очертить площадь будущей разработки.
Как я запустил собственный ML-стартап
Сейчас я развиваю собственные проекты, связанные с машинным обучением и не только, — среди них русскоязычная версия игры Wordle, приложение для подбора подарков на основе интересов из «ВКонтакте» с помощью нейросети и другие.

Так выглядят рекомендации подарковСкриншот: Giftbox
Идея создать Giftbox пришла ещё несколько лет назад. Дело в том, что в декабре и январе у многих моих близких дни рождения. Выбор подарков для них отнимал много времени. Я человек ленивый, поэтому решил сделать приложение, которое автоматически подбирает идеи. Занимался им около месяца по вечерам после работы.
Из ML-фреймворков использовал TensorFlow, дополнительно разобрался с MLflow — это такой опенсорс-инструмент для запуска ML-моделей в продакшен.
Я определил около 80 интересов, сделал список групп и подписок и собрал нейросеть через VK API по ключевым словам, которые соответствуют каждому интересу. Потом с помощью фрилансеров распределил группы по темам (разметил данные). Например, ключевое слово «дизайн» может относиться к веб-дизайну, а может к дизайну интерьеров — это разные темы. Также я поручил фрилансерам проверить работу друг друга.
Всего было обработано около 40 тысяч источников.
Чтобы людям было проще, я сразу выгрузил все нужные данные в CSV. Это позволило делать всё прямо в «Google Таблицах», что существенно ускорило процесс. Часть данных использовалась для обучения классификационной нейросети, а часть — для оценки качества обучения. Приложение Giftbox работает в партнёрстве с онлайн-магазинами. Нейросеть подбирает подарок исходя из действий пользователя на его странице и его интересов.

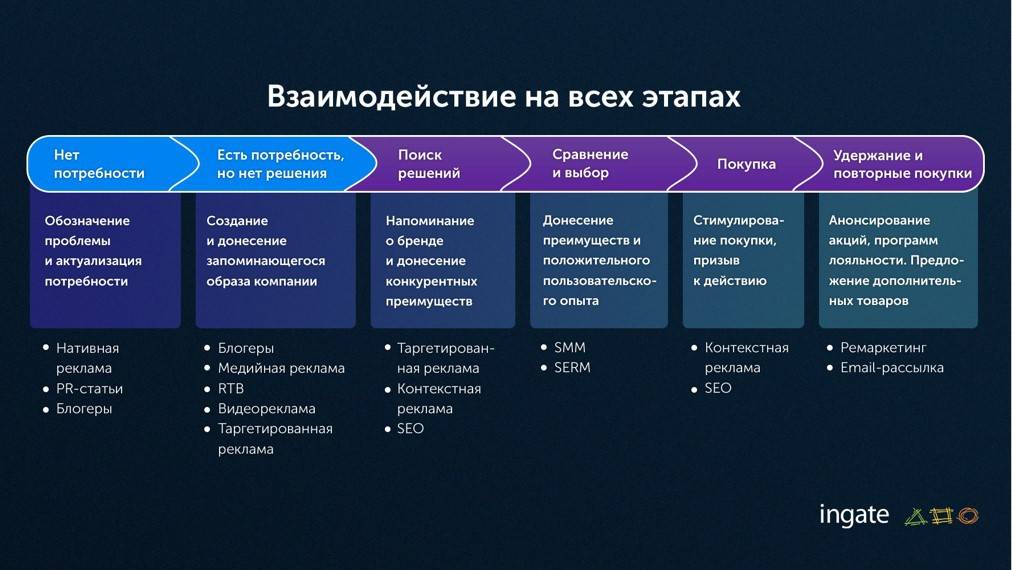





Процесс обучения нейросети
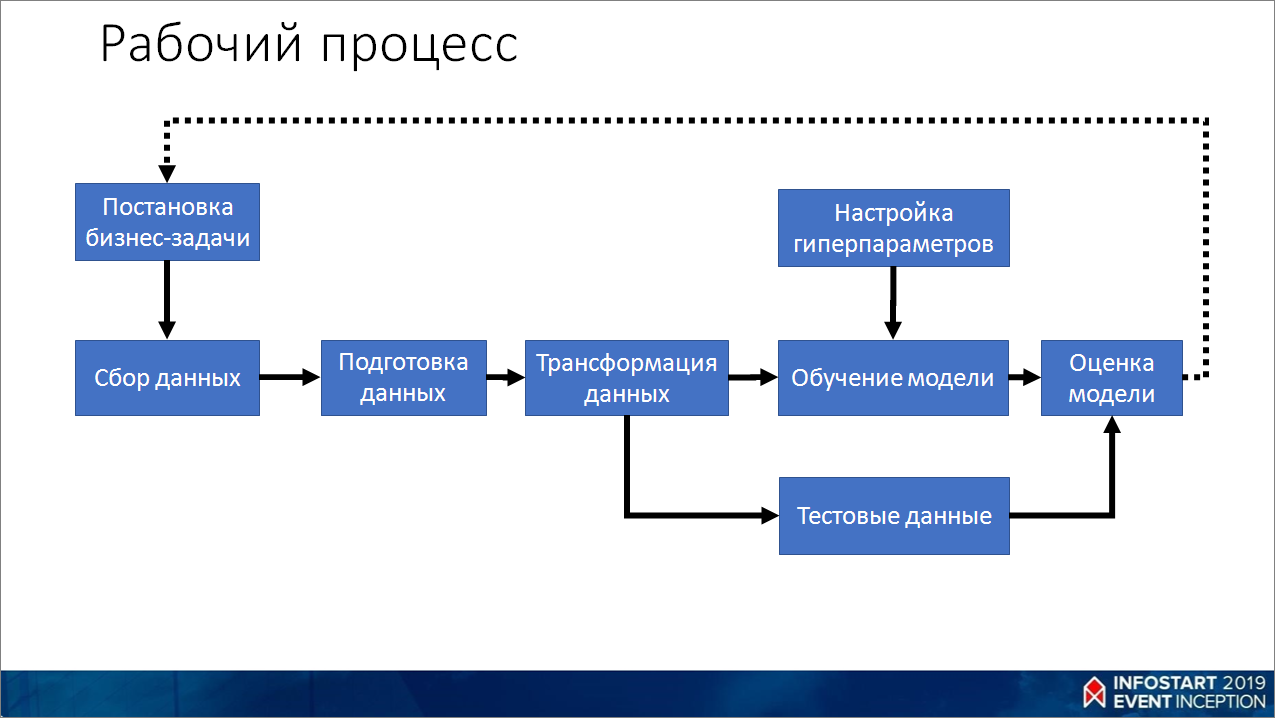
Расскажу немного про процесс, как мы обучаем.
- Формулируем задачу, проверяем ее адекватность и возможность реализации. Как можно быстро приближенно проверить адекватность? Если посадить человека и дать ему эту задачу, и он сможет, не задумываясь, ее решить за одну секунду, то, скорее всего, машинное обучение с этим тоже справится. И, как правило, оно потом будет делать это лучше, чем человек. И не уставать.
- В зависимости от задачи смотрим, есть ли у нас данные. Если нет – начинаем собирать. Либо где-то приобретаем.
- Данные нужно подготовить, убрать пропуски и преобразовать в какой-то структурированный вид.
- Дальше мы трансформируем наши данные. Практически все алгоритмы не умеют работать с данными и с текстом в прямом виде – необходимо преобразование в числовые значения. Трансформация заключается в том, что мы переводим:
- тексты – в векторы чисел;
- картинки – в пиксели;
- числовые значения приводим к шкале от -1 до 1 (или от 0 до 1).
- Делим эти данные на две части – тренировочные и тестовые.
- На тренировочных данных обучаем модель и оцениваем результаты.
- Если что-то не очень хорошо идет, подкручиваем гиперпараметры. Поясню, что такое гиперпараметры. Если вы вспомните слайд, где был показан нейрон, там были коэффициенты, которые мы умножаем на входящие значения. Во время обучения мы их подстраиваем. Это будут параметры – то, на что мы не можем влиять, оно само формируется в процессе обучения. Это некий «черный ящик». А гиперпараметры – это ручки к этому ящику, мы можем их подкрутить и как-то донастроить сеть в процессе обучения.
- После того, как мы модель обучили, проверяем ее на тестовых данных. Зачем вообще нужны тестовые данные? Они нужны, чтобы как-то сэмулировать появление новых данных, которых до этого не было, и избежать ситуации, когда при появлении новых данных в продакшен мы получим что-то неработающее. Самое главное – никогда не показывать тестовые данные во время обучения. То есть, мы забыли о них, отложили, получили какую-то модель в ходе обучения, а потом проверяем по тестовым данным.
- В результате получаем какую-то финальную оценку. Если она адекватная, то можно попробовать выкатить это в прод, посмотреть, как все это будет работать. Если нет, то возвращаемся в самое начало, возможно, даже придется переформулировать задачу, потому что она не реализуема в текущий момент. И так далее – все это в цикле может повторяться.
Интегрируем веб-сервис с 1С

В 1С это выглядит так.
Используется библиотека КоннекторHTTP (//infostart.ru/public/709325/), которую я написал – я за вас уже половину работы сделал.
Вы берете текст, передаете его в метод PostJson() и получаете ответ.
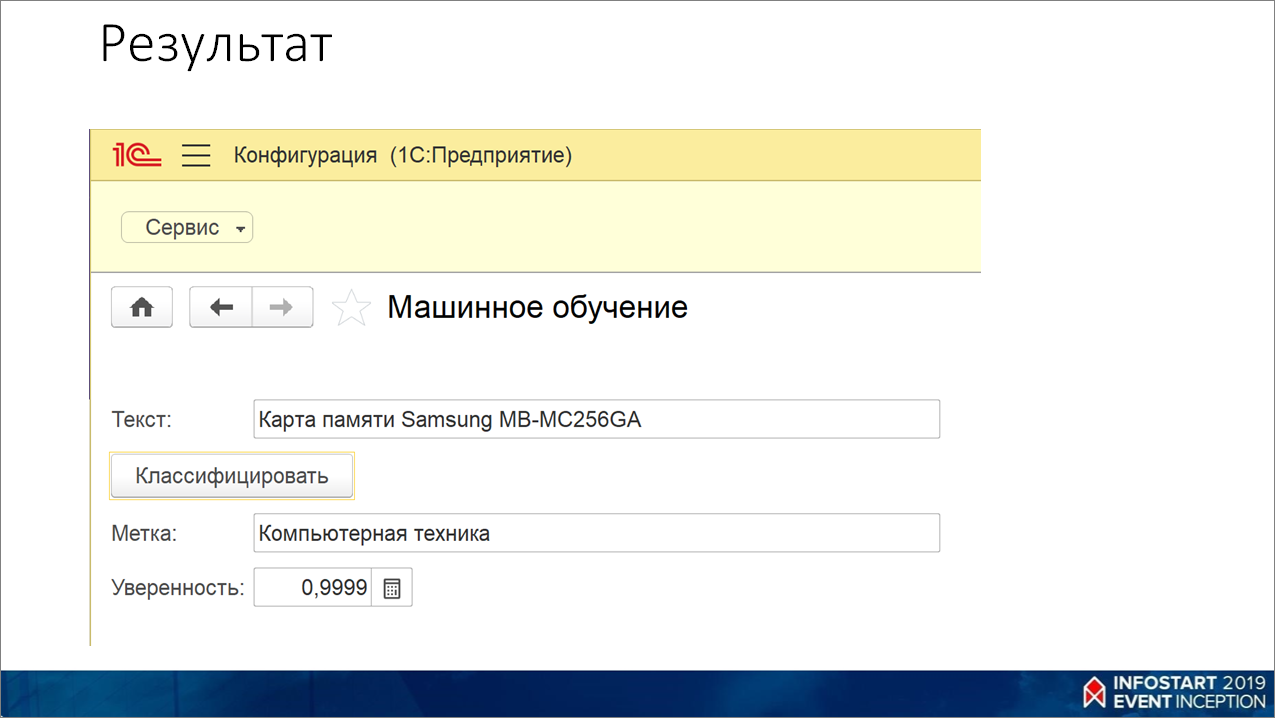
Вот так это приблизительно выглядит. Видно, что карта памяти – это у нас компьютерная техника с уверенностью практически 100% (от 0 до 1).
Например, если бы я убрал «памяти», убрал «Samsung», она бы все равно предсказывала, что это – компьютерная техника, просто уверенности было бы меньше.
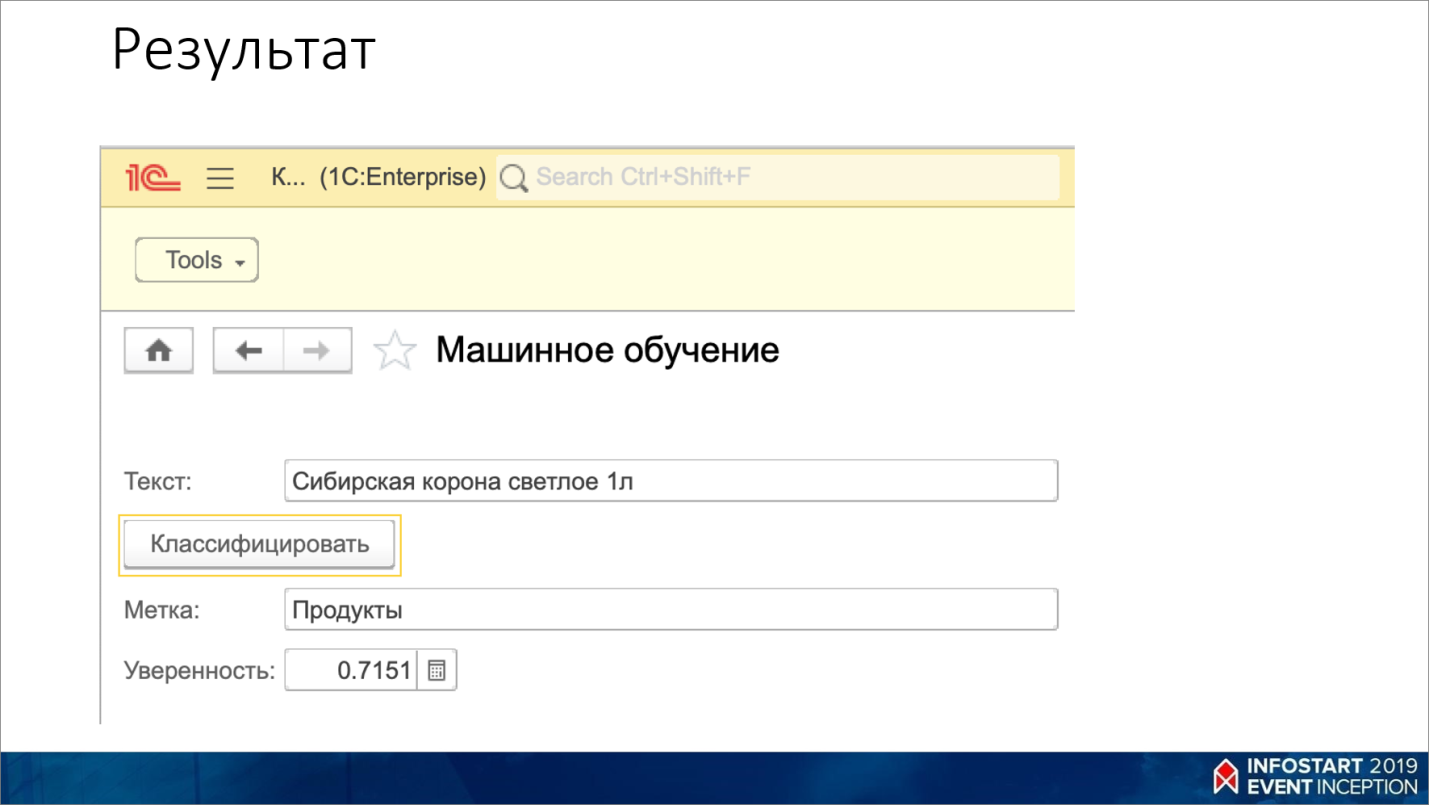
Например, я пробовал «Сибирская корона светлое 1л», и она уже понимает, что это – пиво.
Мой подход
Я чаще всего организовываю структуру на основе третьего подхода, но учитывая особенности конкретного проекта. Попробуем описать, как может выглядеть такая структура.
Корневая папка
Корневая папка проекта может выглядеть следующим образом. Папка scr содержит весь исходный код для работы с проектом. Она включает в себя файлы:
- train.py— код для чтения параметров и путей из конфигурационного файла, обучение модели с последующей ее сериализацией и сохранением логов;
- predict.py —код для загрузки модели, расчета метрик на данных и их сохранение;
- preprocess.py— код для препроцессинга и разбиения датасета, если этого требует задача.
По необходимости в папку добавляются и другие файлы с исходным кодом
Важно организовать код так, чтобы для проведения новых экспериментов требовалось лишь поменять параметры в конфигурационном файле, без изменения кода
Структура проекта
Директория notebooks хранит Jupyter Notebook для удобной визуализации данных или других манипуляций с данными, которые удобнее делать в интерактивном режиме.
В папке data будут находиться все данные для экспериментов: исходные, обработанные, с добавлением новых признаков и т. д. Иногда для удобства в ней создаются подпапки, например, с датами получения данных. Либо исходные данные помещаются в папку source, а подготовленные для входа в модель — processed.
Experiments — директория с экспериментами. Для любого изменения в модели, даже одного гиперпараметра, необходимо создавать новую подпапку эксперимента. Каждая подпапка с экспериментом содержит:
- config.yaml — конфигурационный файл. Может быть в любом структурированном формате, например, JSON или XML, содержит все данные для запуска эксперимента: путь до использованного датасета, гиперпараметры модели, тип обучаемой модели, название и путь для сохранения обученной модели и логов, любые другие параметры для запуска кода;
- trained_model— обученная модель машинного обучения;
- metrics.yaml— как и конфигурационный файл, может быть в любом структурированном виде, удобном для команды проекта, хранит метрики модели на путь до датасетов, на которых они были получены, и путь до модели, с помощью которой выполнялись предсказания.
- logs.md— логи, записанные в процессе обучения модели.
Requirements.txt — список библиотек и фреймворков, которые необходимо установить для запуска проекта.
Example_config.yaml — пример конфигурационного файла для запуска проекта. Нужен для понимания командой, какие поля, типы данных в них и какую структуру должен иметь файл для успешного запуска проекта.
Makefile — нужен для запуска очередного эксперимента, может быть заменен на main.py файл, но важно,чтобы была возможность запустить проект из консоли, просто указав путь до папки с экспериментом, т. к
очень часто обучением моделей приходится заниматься на серверах с терминальными операционными системами.
Readme.md — описание структуры проекта, используемого окружения и информации, как запустить код и увидеть результаты.



К проекту также можно добавить файлы: для работы с git-репозиториями, например .gitignore, makefile — разные, например для проверки кодстайла.
Такая структура сэкономит ваше время, позволит не потерять результаты каждого эксперимента, включая его метрики и конфигурацию модели. Это позволит в любой момент обучить модель, показавшую наилучшие метрики, просто взяв сохраненный конфигурационный файл, либо использовать сохраненные веса модели.
Предварительные выводы о решении проблем безопасности ИИ
Это исследование пока находится на ранней стадии, но мы полагаем, что собранные на сегодняшний момент материалы свидетельствуют о том, что более глубокое изучение каждой из указанных ниже областей будет иметь ключевое значение для продвижения нашей отрасли к более надежным и безопасным продуктам и услугам на базе искусственного интеллекта и машинного обучения. Ниже приведены наши первые выводы и мысли о том, что хотелось бы сделать в этой области.
Результаты тестирования на проникновение и проверки безопасности на основе искусственного интеллекта и МАШИНного обучения можно создать для обеспечения того, чтобы наши будущие ИИ разделяют наши ценности и соответствуют принципам ИИ Asilomar.
Такая группа специалистов могла бы также разработать инструменты и инфраструктуру, которые можно было бы использовать в масштабах всей отрасли для обеспечения безопасности служб на основе искусственного интеллекта и машинного обучения.
Со временем этот экспертный опыт будет естественным образом накапливаться в командах инженеров, как это было с традиционными знаниями в области безопасности в последние 10 лет.
Можно разработать модели обучения, которые позволят предприятиям достигнуть демократизации ИИ и одновременно решить проблемы, обсуждаемые в этом документе.
Специальные модели обучения для обеспечения безопасности ИИ предполагают, что инженеры знают о рисках, связанных с их искусственным интеллектом и используемыми ресурсами. Такие материалы необходимо предоставлять ИИ вместе с текущим обучением по защите данных клиентов.
Чтобы этого достичь, не нужно каждому специалисту по обработке данных становиться экспертом по безопасности
Вместо этого следует основное внимание уделить разработчикам и обучить их принципам устойчивости и избирательности, применимым к их вариантам использования ИИ.
Разработчики должны будут понимать составные элементы системы безопасности служб ИИ, которые будут повторно использоваться на их предприятии. Необходимо сделать упор на создании отказоустойчивых моделей с подсистемами, которые можно легко отключить (например, обработчики изображений или анализаторы текста).
Классификаторы машинного обучения и лежащие в их основе алгоритмы могут быть усилены способностью обнаруживать вредоносные данные, не смешивая их с текущими достоверными обучающими данными или не искажая результаты.
Для таких методов, как отклонение вредоносных входных данных , необходимы циклы исследований для подробного анализа.
Эта работа включает в себя математическую проверку, проверку концепции на уровне кода и тестирование на наличие как вредоносных, так и безвредных аномальных данных.
Человеческая точечные проверки/модерация могут быть полезными здесь, особенно в тех случаях, когда имеются статистические аномалии.
«Классификаторы-смотрители» могут быть построены так, чтобы они имели более универсальное понимание угроз для различных ИИ
Это значительно повысит безопасность системы, поскольку злоумышленник больше не сможет проникать в какую-либо конкретную модель.
Разные ИИ могут быть связаны между собой, чтобы выявлять угрозы в системах друг друга.
Можно создать централизованную библиотеку для аудита и аналитической экспертизы алгоритмов машинного обучения, которая будет устанавливать стандарты прозрачности и достоверности результатов работы ИИ.
Также может быть добавлена возможность делать запросы для аудита и преобразования решений ИИ, которые оказывают большое влияние на бизнес.
Для выявления троллинга, сарказма и других аномалий, а также реагирования на них, ИИ может постоянно собирать и анализировать жаргон, который используется злоумышленниками из разных культурных групп и в разных социальных медиа.
Искусственный интеллект должен быть устойчивым ко всем видам жаргона, будь то технический, региональный или характерный для какой-то отдельной площадки.
Этот текст знаний также можно использовать в фильтрации содержимого, маркировке и блокировании автоматизации для решения проблем масштабируемости модератора.
Эта глобальная база данных терминов может размещаться в библиотеках разработки или даже предоставляться через API облачных служб для повторного использования различными интерфейсами AIS, обеспечивая преимущества новых интерфейсов AIS от объединенной мудрости старых.
Можно создать платформу для фаззинга алгоритмов машинного обучения, которая даст инженерам возможность добавлять в тестовые обучающие наборы различные типы атак для оценки ИИ.
Это может быть не только аномальный текст, но и изображения, голос и жесты, а также различные комбинации этих типов данных.



