
Случайный лес
Есть проблема: построенное таким образом дерево очень сложное и, вероятно, не очень точное. Попробуем сделать не одно огромное дерево, а несколько небольших.
Возьмём случайную выборку из наших исходных данных. Не миллион клипов, а 10 000. К ним — случайный набор критериев, не все 100, а 5:
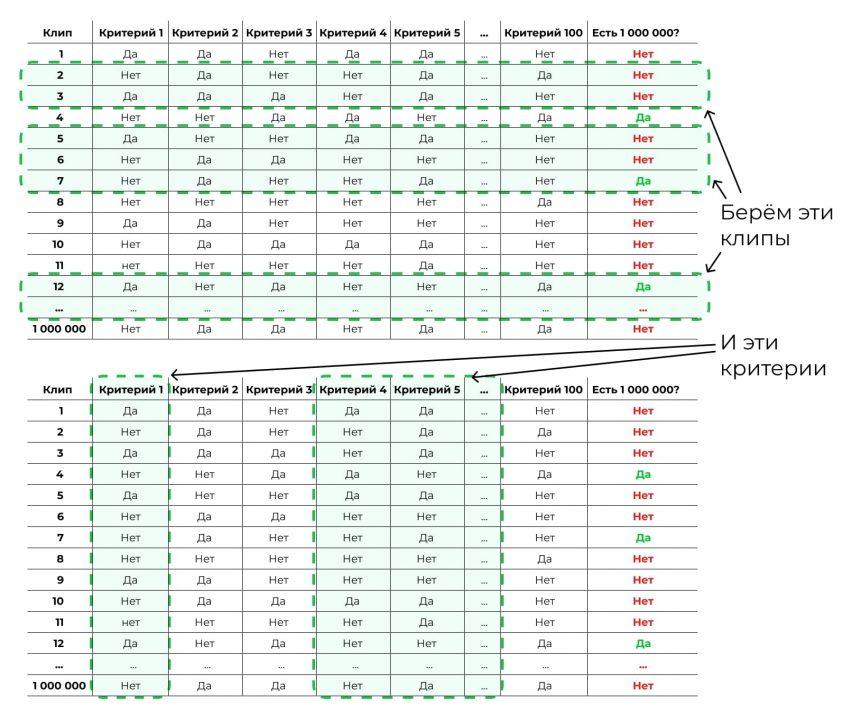
И построим дерево попроще:
 Было много уровней, стало меньше
Было много уровней, стало меньше
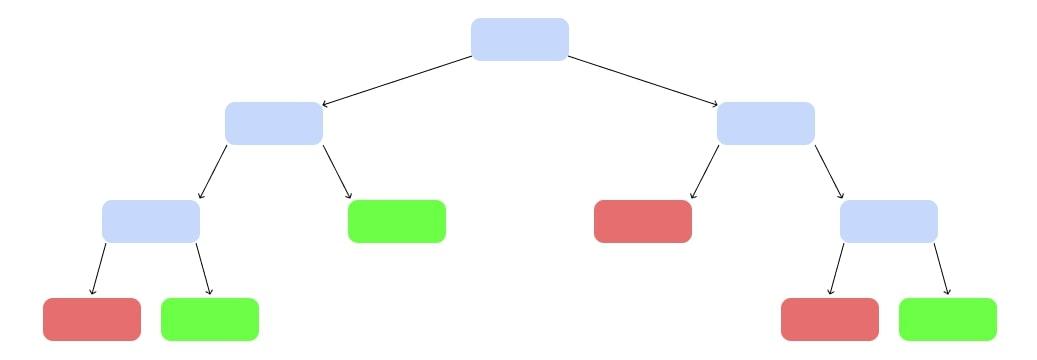
Так построим ещё несколько деревьев, каждое — на своём наборе данных и своём наборе критериев:
 Лес алгоритмов
Лес алгоритмов
У нас появился случайный лес. Случайный — потому что мы каждый раз брали рандомный набор данных и критериев. Лес — потому что много деревьев.
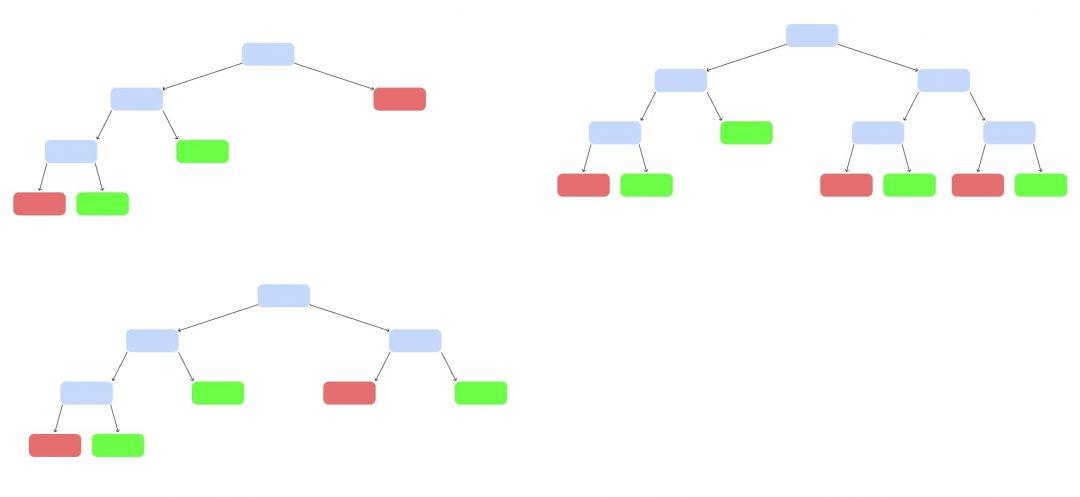
Теперь запустим клип, которого не было в обучающей выборке. Каждое дерево выдаст свой вердикт, станет ли он популярным — «да» или «нет». Как голосование на выборах. Выбираем вариант, который получит больше всего голосов.
 Три за, один против — клип ждёт успех. Наверное
Три за, один против — клип ждёт успех. Наверное
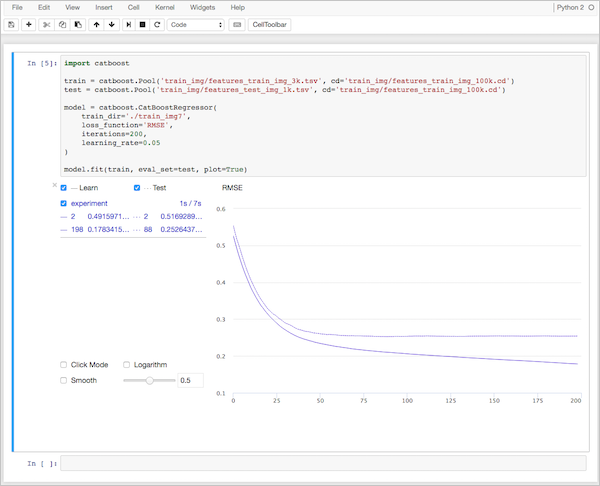
Build the CatBoost regression model on diamonds data
Here, is the code.
Wait till loading the code!![]()
(Image by author)
Is this a good value? This is the standard deviation of prediction errors (residuals). The lower the value, the better the model. Let’s look closer at the price variable.
y.describe()
(Image by author)
The range (max-min) is 18497. The standard deviation is 3989. So, the RMSE value we got is a really good one for our model. Also, note that we got this value without doing any hyperparameter tuning!
LightGBM with categorical features
In Part 5, we’ve discussed that LightGBM can also be used directly with categorical features without encoding. But, LightGBM does not have any internal mechanism to handle categorical features.
Let’s see what happens if we use LightGBM with categorical features.
Wait till loading the code!
(Image by author)
You’ll get a value error saying that you should encode categorical values into numerical values.
But, wait! There is an easy method with LightGBM. We do not need to encode our categorical values. Instead, we just need to do a datatype conversion (object datatype → category datatype) for X before training the algorithm.
ДВА МИЛЛИОНА ВОСЕМЬСОТ ПЯТЬДЕСЯТ ТЫСЯЧ, КАРЛ!
Это мы дословно цитируем слайд Ивана Дрокина. Он описывал, сколько рублей пришлось бы потратить в конкретном проекте, если для определения положения деталей на рабочей поверхности вместо компьютерного зрения использовался бы труд живых разметчиков.
Дальше он переходил к основному содержанию доклада, показывая, что если под рукой нет подходящего датасета с реальными фотографиями, чтобы «натренировать» на них, то возможно использовать искусственно сгенерированные. Но замечание о деньгах по-своему показательно. Работа с «большими и умными данными» отчасти связана с академическим миром, и на SmartData выступал, например, Алексей Потапов из ИТМО, однако конференция не превращалась в научный симпозиум, оторванный от приземлённых земных материй вроде денег. Здесь многое было посвящено не абстрактным данным в вакууме, а реальным индустриальным задачам, где значение имеет как размер датасета, так и размер бюджета.
Работа с датасетом
Режимов выборки данных
CatBoost поддерживает несколько режимов выборки данных
- Бутстрап (англ. bootstrap) Бернулли — выбираем документ с вероятностью p. Регулируется параметром sample_rate;
- Байесовский бутстрап — байесовское распределение. Регулируется параметром bagging_temp.
Отметим, что бутстрап используется только для выбора структуры дерева, для подсчета значения в листьях используем всю выборку. Это сделано, так как выбор структуры дерева происходит долго, нужно несколько раз пересчитывать значения, поэтому использовать всю выборку слишком дорого. Однако значения в листьях с уже готовой структурой дерева считаются один раз, и для большей точности можно позволить использовать весь датасет.
Бинаризация признаков
Пробовать все — долго. Поэтому выбираем сетку заранее и ходим по ней.
Есть несколько способов выбора:
- Uniform. Равномерно разбиваем отрезок от минимума значения для данного признака до максимума;
- Медианная сетка. Задаем количество разбиений над множеством значений, далее идем по объектам в порядке сортировки и разбиваем на группы по k объектов, где k — количество объектов в одном слоте разбиения;
- UniformAndQuantiles. Комбинация 1 и 2 пунктов;
- MaxSumLog — в основе лежит динамика, работает долго;
- GreedyLogSum — аналог MaxSumLog, используется жадный алгоритм, поэтому работает не точно, однако быстрее чем MaxSumLog.
Работа с категориальными признаками
- LabelEncoding — на реальных примерах точность работы низкая, так как появляется отношения порядка между объектами;
- One-hot encoding — дает неплохую точность, если различных значений признаков не много. Иначе один признак размножится на множество признаков и будет влиять на модель заведомо сильнее остальных признаков.
Лучше не делать препроцессинг самим из-за проблем, описанных выше. В CatBoost можно задать параметр cat_features, передав туда индексы категориальных признаков. Также можно отрегулировать параметр one_hot_max_size — максимальное количество различных значений у категориального признака, чтобы он мог в последствии быть подвержен one-hot encoding.
The diamonds dataset
Now, we’ll look at some important details of the “diamonds” dataset.
import pandas as pddf = pd.read_csv('diamonds.csv')df.head()
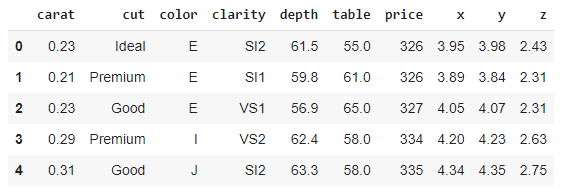
(Image by author)
Let’s find out some information on the features (variables) in the dataset.
df.info()
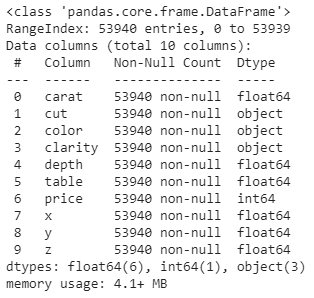
(Image by author)
As you can see, the variables cut, color and clarity are categorical variables. They all have the object datatype. These categorical variables do not have numerical values. Usually, we need to encode them into numerical values because most of the algorithms only accept data with numerical values during the training process.
But, this is not the case for CatBoost. We can directly use categorical features with CatBoost without encoding them. For this, we need to convert our data into CatBoost’s special Pool datatype by using the Pool() class. We also need to specify the names of categorical features in the cat_features parameter.
We can also use CatBoost without converting our data into the Pool datatype if our data has only numerical features. If our data has categorical features, we must convert our data into the Pool datatype before using CatBoost.
The designing process of a CatBoost model on the diamonds data is straightforward. We can select the price variable as the target column (y) and the remaining variables as the feature matrix (X). We also remove the table, x, y and z variables from the dataset as they do not provide much value to the data. Then, we can define X and y as follows:





X = df.drop(columns=)y = df
Because the price is a continuous-valued variable, here we need to build a regression model (actually a CatBoost regression model!). To build the model, we use the CatBoostRegressor() class with its relevant hyperparameter values. For classification tasks, there is a separate class called CatBoostClassifier().
Для чего Шредингер это придумывает?
В квантовой механике считается, что если за ядром никто и ничто не наблюдает, то он находится в смешанном, неопределенном состоянии. И распавшемся, и не распавшемся сразу. А вот когда появляется наблюдатель, ядро оказывается в одном из состояний. Кстати, эксперимент Шредингера имел цель – выяснить, в какой именно момент «кот одновременно мертвый и живой». А также когда выявляется конкретное состояние. Ученый хочет доказать, что квантовая механика невозможна без тонких деталей. А они определяют, при каких именно условиях случается коллапс волновой функции (изменение состояния). А также определяют, когда объект остается в одном из возможных состояний (никак не в нескольких сразу).
Эрвин Шредингер хотел указать на странное заключение квантовых теоретиков. Они считали, что обычный человек может увидеть истинное состояние материи невооруженным глазом. Копенгагенская интерпретация квантовой физики была доминирующей в то время. Она считала, что атомы или фотоны существуют в нескольких состояниях в один момент (находятся в суперпозиции) и не переходят в определенное, пока они не наблюдаются.

Эксперимент Шредингера гововит о том, что наблюдатель не может знать, распался атом вещества или нет. К тому же наблюдатель не знает, разбился ли флакон и погиб ли кот. В соответствии с копенгагенской интерпретацией, кот будет жив и мертв, пока кто-то не заглянет в коробку. В квантовой механике способность кошки быть живой и мертвой до тех пор, пока ее не наблюдают, называется квантовой неопределенностью или парадоксом наблюдателя. Логика, лежащая в основе парадокса наблюдателя, заключается в том, что наблюдения могут определять результаты.
Шредингер согласился с тем, что суперпозиция существует. Кстати, при его жизни ученые смогли доказать это, изучая интерференцию в световых волнах. Но он задавался вопросом о том, когда на самом деле суперпозиция сменяется определенным состояние. Эксперимент Шредингера заставил людей задаться вопросом. На самом ли деле возможно определить исход жизни кота, открыв коробку (посмотреть на него)?

1 Сева Жидков
Разработчик ботов для портала «Медуза» и Mail.ru Group Сева Жидков закончил в этом году 9 класс. Сейчас ему 16, и он — самый молодой сотрудник команды «ВКонтакте», где занимается машинным обучением (в частности, пишет боты, которые раздают стикеры.)
 Сева Жидков
Сева Жидков
Год назад Сева (еще обучаясь в школе) создал чат-бота «Leonard» — виртуального помощника для «Telegram» и «ВК». Бот обладает разнообразным спектром возможностей: умеет находить нужные сведения в Интернете, вызывать такси, составлять новостные сводки. Примерно в то же время Сева создал приложение, которое помогает искать пропавших животных.
После того, как «Leonard» был сконструирован и запущен, Сева рассказал о нем СМИ, что принесло боту известность (в первый день им воспользовались более 1000 человек). Однако на работу во «Вконтакте» Сева устроился самостоятельно, без чьей-то помощи и особых приглашений.
В будущем Сева хочет создать развитую интеллектуальную систему ботов, которые смогут взаимодействовать между собой и принимать решения по самым разным вопросам, подобно человеку.
2 Михаил Биленко
Специалист в области искусственного интеллекта и машинного обучения Михаил Биленко известен не так широко, как новый российский бот, в разработке которого он участвовал — голосовой помощник «Алиса» от компании «Яндекс». Приложение стало доступно для пользователей 10 октября.
 Михаил Биленко
Михаил Биленко
Бот может отвечать на вопросы пользователя как собеседник или выдавать запрашиваемую информацию как поисковик. Недавно «Алиса» пообщалась даже с президентом.
Михаил работает в «Яндексе» с января 2017 года, занимаясь руководством исследований в области машинного интеллекта. Он имеет богатый опыт разработки технологий ИИ — ранее он обучался в Техасском Университете США и работал в штаб-квартире Microsoft, город Рэдмонд. Неудивительно, почему в «Яндексе» им заинтересовались.
 Штаб-Крартира компании Microsoft в Рэдмонде
Штаб-Крартира компании Microsoft в Рэдмонде
Для России голосовой помощник, созданный компанией «Яндекс» — первый проект по внедрению технологий ИИ в общедоступное приложение. Сейчас Биленко вместе с командой продолжают обучать «Алису» и совершенствуют механизмы программы, шлифуя «неровности».
20700
Столько просмотров у августовского хабрапостаВиталия Худобахшова, который лёг в основу открывающего кейноута SmartData. Наблюдение, что люди с разными именами оказываются одинокими с ощутимо разной частотой, впечатляет своей контринтуитивностью: на это немедленно хочется возражать. Но доклад отличался от поста как раз тем, что учитывал возникшие после поста возражения: оказалось, что первые приходящие в голову варианты вроде «это боты картину исказили» не подтверждаются.
В итоге первое выступление конференции получилось одновременно и забавным, и в то же время вполне серьёзно подходящим к вопросу, там было и над чем посмеяться, и над чем задуматься.
Космическая погода
 Татьяна Подладчикова, старший преподаватель Космического центра Сколтеха, кандидат технических наук, прикладной математик, лауреат международной медали Александра Чижевского по космической погоде и космическому климату (Фото — Леонид Сорокин/Inc)
Татьяна Подладчикова, старший преподаватель Космического центра Сколтеха, кандидат технических наук, прикладной математик, лауреат международной медали Александра Чижевского по космической погоде и космическому климату (Фото — Леонид Сорокин/Inc)
Татьяна Подладчикова занимается изучением Солнца и космической погоды с применением ИИ. Космическая погода требует постоянного мониторинга деятельности Солнца и космического пространства и направлена на разработку оперативных сервисов прогнозирования и уменьшения последствий экстремальных космических погодных явлений, объясняет она. Однако разработка и совершенствование сервисов космической погоды требует углубленных исследований в области солнечно-земной физики, понимания процессов на Солнце и всех тонкостей взаимодействия между Солнцем и Землей.
| Методы быстрой классификации и анализа потока солнечных изображений, над которыми мы работаем в нашей лаборатории совместно с международными коллегами, позволяют детектировать мощные выбросы солнечной массы, а также предсказывать их прибытие на Землю. В случае сигнала тревоги, как правило, выключают чувствительное оборудование спутников, которые летают вокруг Земли. Наши разработки и сервисы по прогнозированию солнечной активности используются для оценки уровня радиации на высоте полета самолетов, — рассказала Татьяна Подладчикова TAdviser. |
По ее словам, совместно с Европейским космическим агентством также ведется разработка нового сервиса прогнозирования радио потока от Солнца, что имеет большое практическое значение для оценки времени возвращения космических аппаратов на Землю, корректировки орбит спутников, предупреждения столкновений и моделирования космического мусора. А совместно с университетом Граца, Австрия, идет работа над созданием сервиса прогнозирования высокосортного солнечного ветра у Земли и связанных с ними геомагнитных бурь.
Кроме того, в рамках большого европейского проекта по созданию 4-метрового наземного солнечного телескопа лаборатория работает над алгоритмами изображений, получаемых с разных наземных станций для обеспечения высококачественных наблюдений и детектирования вспышек на Солнце. Новые достижения в области искусственного интеллекта позволяют усовершенствовать изображения более низкого качества, полученных телескопами прошлого поколения на основе новых качественных данных современных телескопов, объясняет Татьяна Подладчикова.
Серия непрерывных наблюдений с наилучшим качеством в течение длительного времени позволит глубже понять ключевые механизмы сложных физических процессов на Солнце, что в свою очередь позволит усовершенствовать операционные сервисы прогнозирования космической погоды, говорит она.
Что привлекает женщин в этой сфере
Стремление быть в гармонии с окружающим миром вызывает интерес человека к пониманию сути наблюдаемых явлений, их закономерностей и предвидению дальнейшего развития событий, говорит Татьяна Подладчикова из Космического центра Сколтеха. В основе знаний об окружающем мире лежат наблюдение и эксперимент. Каждый день мы получаем большое количество ценных данных. Однако большая часть информации теряется, поскольку мы не можем обрабатывать данные достаточно эффективно, отмечает она.
| В последние годы методы искусственного интеллекта достигли замечательных результатов. И это настоящий успех, когда мы можем получить новое полезное знание из данных, ведущих к пониманию сути наблюдаемых явлений, контролю и прогнозированию будущего развития событий. А также прийти к надежным решениям, принимаемым на основе полученных результатов, — объясняет Подладчикова свой интерес к этой сфере. |
Поток текстовых и других данных растет с каждым днем, и кому-то нужно эти данные обрабатывать и извлекать из них что-то полезное, говорит Анастасия Кравцова из Лаборатории нейронных систем и глубокого обучения МФТИ.
| Кроме того, растет спрос на диалоговых ассистентов и автоматизацию коммуникации в целом, когда обращения обрабатываются без участия живого человека, так что перспектива делать жизнь людей проще не может не вдохновлять, — отмечает она. |
Когда Анна Калюжная, ныне руководитель научного подразделения в Национальном центре когнитивных разработок Университета ИТМО, окончила обучение в вузе, ей хотелось найти работу, которая, с одной стороны, предложила бы ей вызов — предполагала регулярное решение интересных задач, а, с другой, стала бы тем местом, где она могла бы приносить пользу обществу. Она посоветовалась с научным руководителем, и он рассказал ей про Александра Валерьевича Бухановского, директора Национального центра когнитивных разработок, и те научные проекты, которые он развивает. Таким образом, Калюжная начала свой научный путь.
Екатерина Серажим из «Яндекса» машинным обучением заинтересовалась еще будучи студенткой в университете. В то время это еще не было таким заметным направлением, говорит она, и в «Вышке» на прикладной математике была всего пара-тройка курсов на эту тему.
| Один из них меня настолько заинтересовал, что я занялась научной работой в этом направлении. Уже тогда, в студенческие годы, меня поразило то, насколько круто алгоритмы машинного обучения могут решать практические задачи вроде прогнозирования погоды или поиска объектов на изображении. Это казалось какой-то магией. Я решила углубить свои знания и поступила учиться в Школу анализа данных (ШАД). После ее окончания выбор пойти работать в «Яндекс» стал для меня очевидным. Ведь здесь можно заниматься чем-то вроде прикладных исследований — придумывать что-то и постоянно экспериментировать, — объясняет Серажим. |
По мнению Ксении Мухиной из Национального центра когнитивных разработок Университета ИТМО, сейчас уникальное время, когда так много данных о том, что происходит вокруг нас, стало доступно для исследований.
| Люди не только изобрели специальные сенсоры, чтобы извлекать информацию об окружающем мире, но и придумали социальные сети, по которым можно понять, что людям интересно и что их привлекает. И если правильно поставить задачу, то можно найти ответ почти на любой вопрос, — объясняет Мухина. |
Екатерина Муравлева из Центра добычи углеводородов Сколтеха рассказывает, что она с отличием закончила мехмат МГУ и защитила диссертацию по вычислительной математике. Может показаться, что многое, чему учат на мехмате — это абстрактные вещи, но на самом деле, у ИИ и классической математики много общих точек. Например, достаточно активно применяются топологические подходы, говорит она.
Для меня важно, чтобы результаты моих исследований были востребованы, чего нельзя сказать о многих теоретических исследованиях. Такой областью на стыке теории и практики фактически стали методы ИИ
Сейчас очень сложно заниматься чем-то, связанным с вычислительными и численными методами, и не интересоваться ИИ, — поясняет Екатерина Муравлева.
А Марии Пукальчик из Центра по научным и инженерным вычислительным технологиям для задач с большими массивами данных Сколтеха эта сфера интересна потому, что машинное обучение и ИИ позволяют точнее, надёжнее и быстрее отрабатывать данные и получать более корректные выводы. Кроме того, это модно, добавила она.





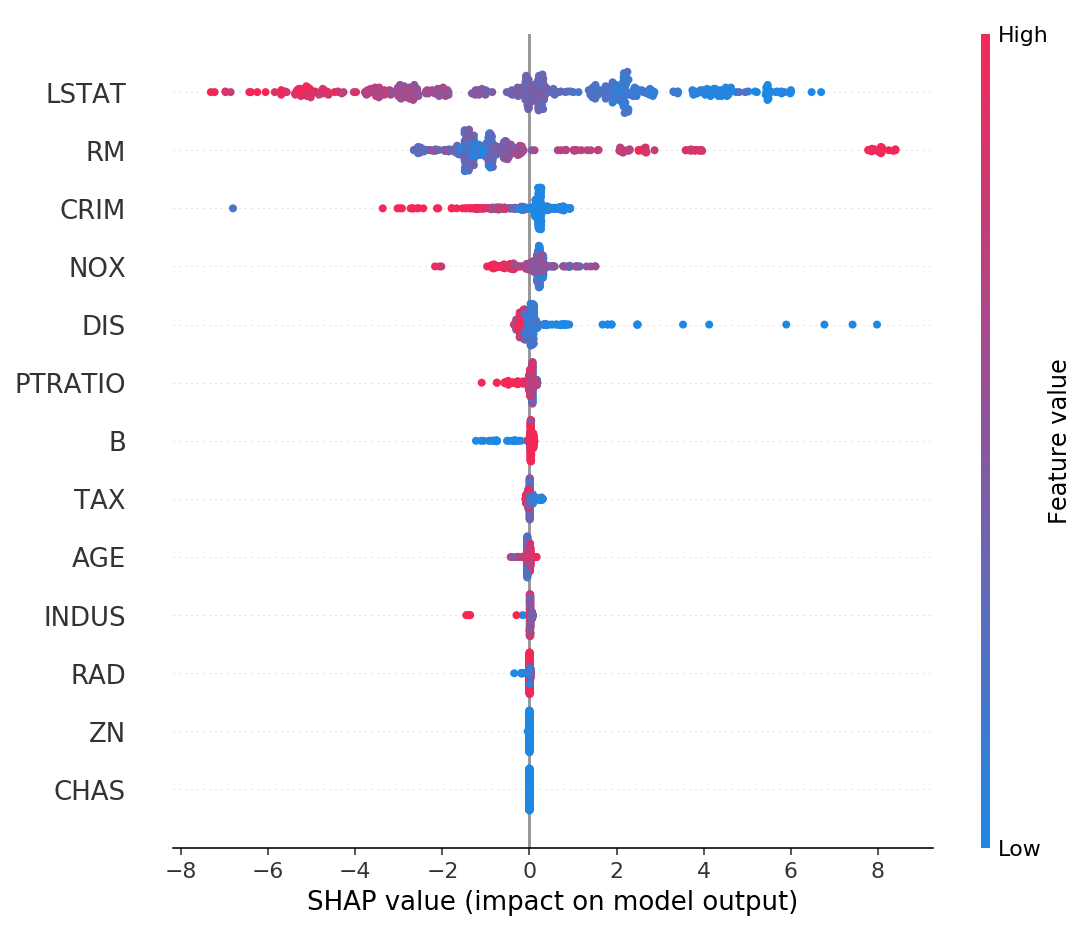
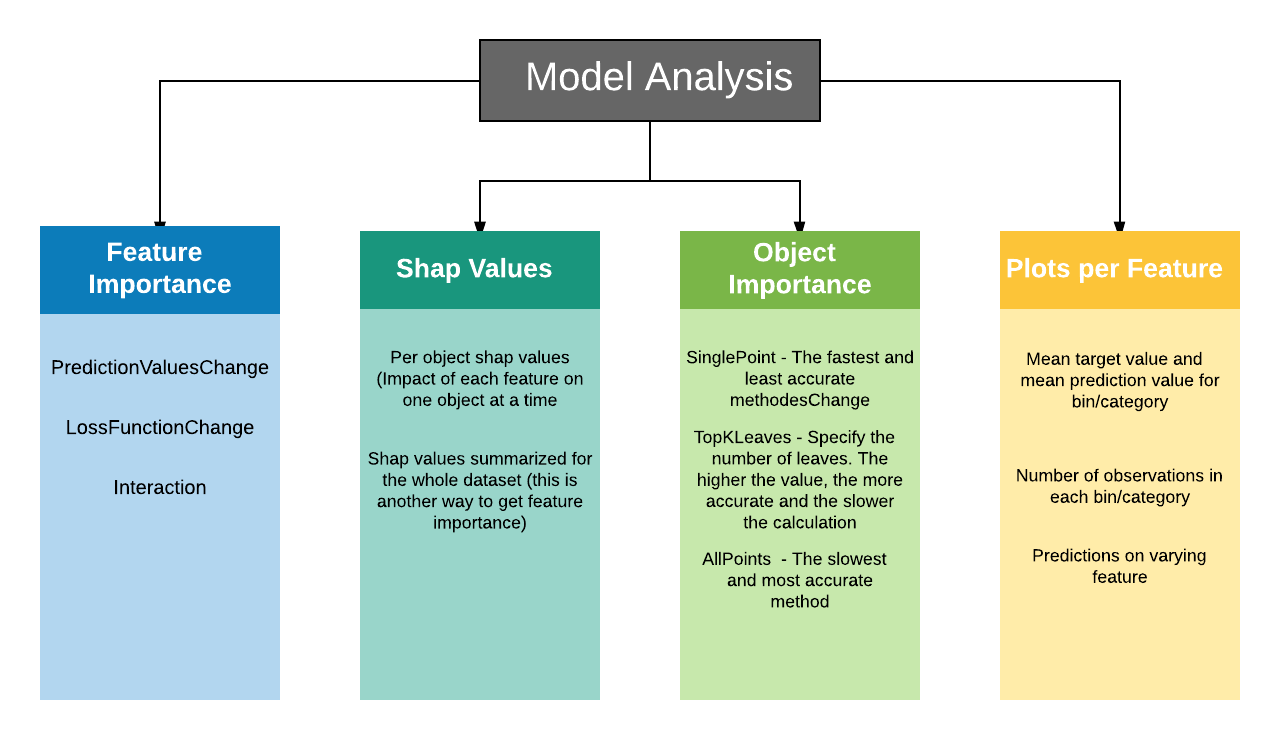
Shap Values
https://github.com/slundberg/shap
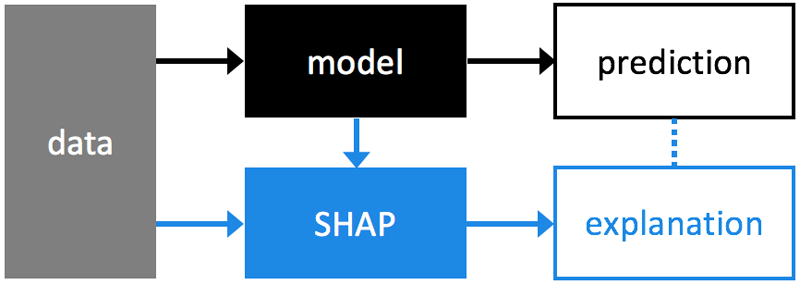
SHAPЗначение разбивает прогнозируемое значение на вклады от каждой функции. Он измеряет влияние элемента на одно значение прогноза по сравнению с базовым прогнозом (средним значением целевого значения для набора обучающих данных).
Два основных варианта использования значений Shap:
- Вклад функций на уровне объекта

https://github.com/slundberg/shap
2 Сводка для всего набора данных (общая важность функции)
shap.summary_plot(shap_values, X_test)
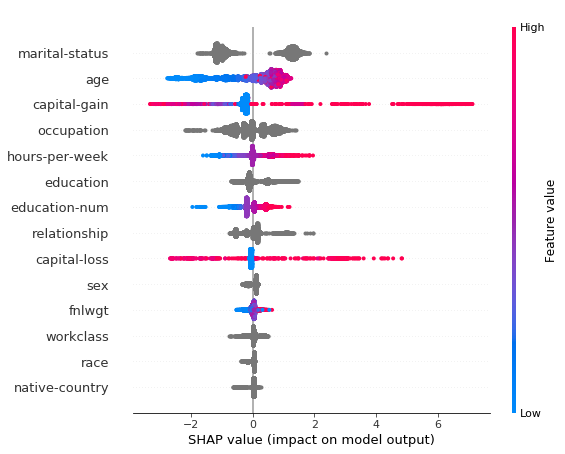
Хотя мы можем получить точные значения функций с помощью Shap, они вычислительно дороже, чем важность встроенных функций Catboost. Для более подробной информации о значениях SHAP, пожалуйста, прочитайте этоядро,. бонусЕще одна важная особенность, основанная на той же концепции, но разной реализации:Важность особенности на основе перестановок,Хотя catboost не использует это, это чистоМодель агностики легко рассчитать
бонусЕще одна важная особенность, основанная на той же концепции, но разной реализации:Важность особенности на основе перестановок,Хотя catboost не использует это, это чистоМодель агностики легко рассчитать
3,5
спикеров от Яндекса было на конференции. Во-первых, уже упомянутая Анна Вероника Дорогуш.
Во-вторых, Артём Григорьев, рассказывавший о краудсорсинге на опыте Яндекс.Толоки. Слово «толока» (форма деревенской взаимопомощи, то есть как раз своего рода краудсорсинг) на gramota.ru даётся с ударением на второй слог, а тут представитель одноимённого сервиса делал ударение на последний. Теперь пытаемся понять, какой же вариант правильный и можно ли узнать это с помощью краудсорсинга.
В-третьих, Владимир Красильщик, который рассказывал о «правильном устройстве» банковской системы, в чём ему помогал ещё «до-яндексовый» опыт. Высказываемые им идеи о том, что надо хранить все события в четырёх временах («время, когда событие произошло, когда мы о нём узнали, и две отметки для интервала его действия»), у некоторых зрителей вызывали возражения — так что после доклада с ним активно дискутировали.
А что с «половиной» спикера? Иван Ямщиков в случае с Яндексом выступает в роли «внешнего консультанта» — так что тут не совсем понятно, как считать. Зато по зрительским отзывам понятно вот что: его закрывающий кейноут о «творческом икусственном интеллекте» понравился аудитории сильнее всего. Тут, как и с открывающим кейноутом, получилось «одновременно весело и серьёзно». Когда слова об «исследовании пространства» иллюстрируют фотографиями детей, тискающих собак, это всем понятно. Когда про такую фотографию говорят, что там фидбэк явно скоро изменится с позитивного на негативный, это вызывает смех:
И когда Иван запускал музыку собственного проекта Neurona, где нейросеть на основе текстов Курта Кобейна сочинила тексты в его духе, это звучит очень доступно. Но серьёзности стоящей за этим работы и того, что человечество получило принциально новые возможности (даже если не считать их «настоящим творчеством»), это никак не отменяет.
Если лидерство выступления Ивана очевидно, то остальной фидбэк от зрителей (пока что продолжающий поступать) нам ещё предстоит как следует обработать и сделать выводы. И когда это сделаем, следующая SmartData окажется ещё умнее, чем первая!
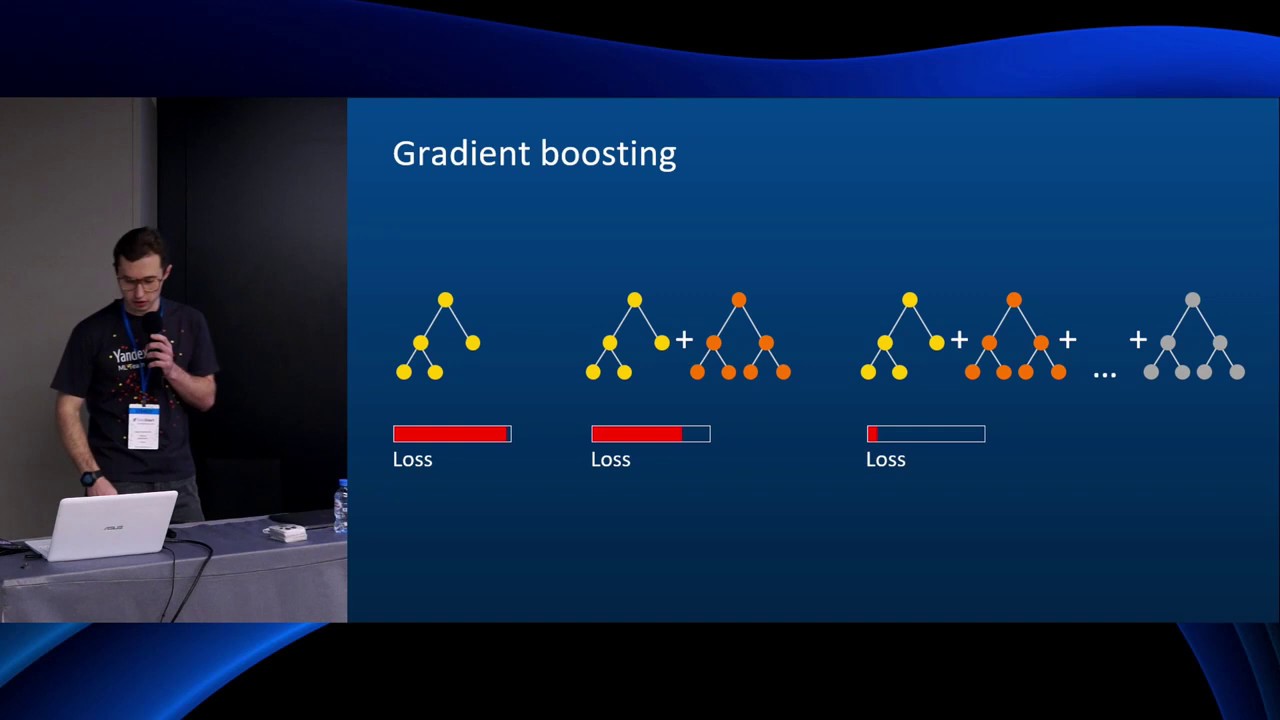
Неслучайный лес — бустинг
Теперь построим похожий лес, но набор данных будет неслучайным. Первое дерево мы построим так же, как и раньше, на случайных данных и случайных критериях. А потом прогоним через это дерево контрольную выборку: другие клипы, по которым у нас есть все данные, но которые не участвуют в обучении. Посмотрим, где дерево ошиблось:
 Первое дерево может давать много ошибок
Первое дерево может давать много ошибок
Теперь делаем следующее дерево
Обратим внимание на места, где первое дерево ошиблось. Дадим этим ошибкам больший вес при подборе данных и критериев для обучения
Задача — сделать дерево, которое исправит ошибки предыдущего.
 Учим дерево исправлять ошибки предшественника
Учим дерево исправлять ошибки предшественника
Но второе дерево наделает своих ошибок. Делаем третье, которое их исправит. Потом четвёртое. Потом пятое. Вы поняли принцип.
Делаем такие деревья, пока не достигнем желаемой точности или пока точность не начнёт падать из-за переобучения. Получается, у нас много деревьев, каждое из которых не очень сильное. Но вместе они складываются в лес, который даёт хорошую точность. Бустинг!
CatBoost пример использования
CatBoost пример кода
Делим данные на тренировочное и тестовое множество
from sklearn.model_selection import train_test_split
X_train, X_validation, y_train, y_validation = train_test_split(X, y, train_size=0.5, random_state=1234) print(X_train.shape, X_validation.shape)
Создаем классификатор
from catboost import CatBoostClassifier
best_model = CatBoostClassifier( bagging_temperature=1, random_strength=1, thread_count=3, iterations=500, l2_leaf_reg = 4.0, learning_rate = 0.07521709965938336, save_snapshot=True, snapshot_file='snapshot_best.bkp', random_seed=63, od_type='Iter', od_wait=20, custom_loss=, use_best_model=True )
Обучаемся
best_model.fit( X_train, y_train, cat_features=cat_features, eval_set=(X_validation, y_validation), logging_level='Silent', plot=True )
Вывод числа деревьев в модели
print('Resulting tree count:', best_model.tree_count_)
> Resulting tree count: 217
Используем скользящий контроль (англ. cross validation)
from catboost import cv
params = best_model.get_params() params = 10 params = 'AUC' del params pool1 = Pool(X, label=y, cat_features=cat_features)
cv_data = cv( params = params, pool = pool1, fold_count=2, inverted=False, shuffle=True, stratified=False, partition_random_seed=0 )
Выводим результат
best_value = np.max(cv_data)
best_iter = np.argmax(cv_data)
print('Best validation AUC score: {:.2f}±{:.2f} on step {}'.format(
best_value,
cv_data,
best_iter
))
> Best validation AUC score: 0.91±0.00 on step 9
Больше примеров кода можно найти на сайте библиотеки CatBoost.
Первый шаг решения
Чтобы построить дерево для такой задачи, мы должны будем сначала посчитать, насколько каждый критерий связан с желаемым результатом:
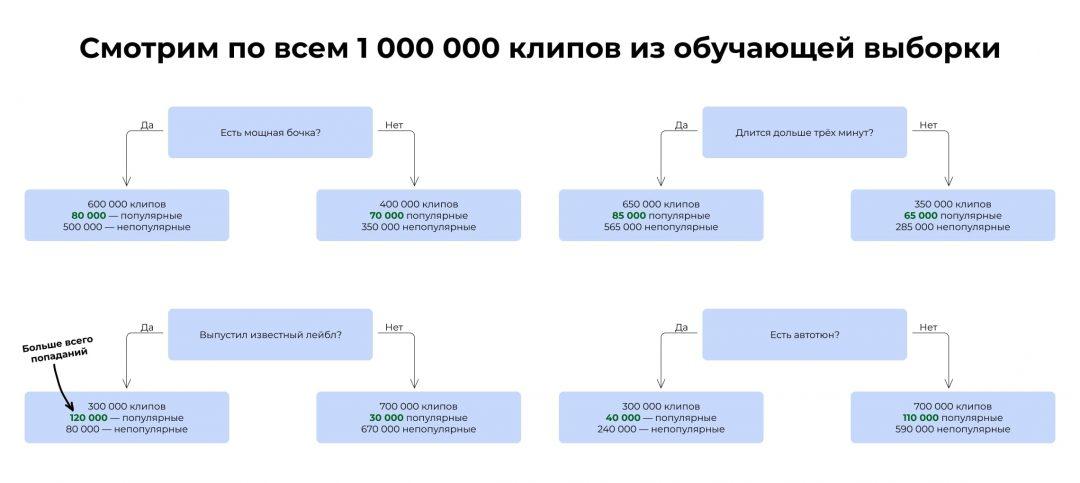 Среди миллиона клипов в обучающей выборке 300 000 выпустили известные лейблы. 120 000 из них стали популярны. Этот критерий лучше других предсказывает популярность
Среди миллиона клипов в обучающей выборке 300 000 выпустили известные лейблы. 120 000 из них стали популярны. Этот критерий лучше других предсказывает популярность



В итоге мы видим, что самая сильная связь с итоговой популярностью у критерия «Выпустил ли клип популярный лейбл». Получается, если клип выпустил лейбл, это влияет на успех сильнее, чем бочка или автотюн. Этот критерий встаёт на вершину дерева.

Затем мы смотрим, какой критерий поставить следующим. Берём те 300 000 клипов, которые выпустили лейблы, и прогоняем их по остальным критериям. Ищем тот, который даёт самую высокую итоговую точность предсказания.
 Среди 300 000 клипов, которые выпустили лейблы, 250 000 клипов идут дольше 3 минут и 90 000 из них набрали больше миллиона просмотров. Этот критерий лучше других предсказывает популярность клипов лейбла
Среди 300 000 клипов, которые выпустили лейблы, 250 000 клипов идут дольше 3 минут и 90 000 из них набрали больше миллиона просмотров. Этот критерий лучше других предсказывает популярность клипов лейбла
Ставим его на второе место.

То же самое делаем для другой ветки. И так строим последовательность из остальных критериев. На практике вручную этим не занимаются: есть специальные алгоритмы, которые делают это автоматически.
Оп, у нас появилось дерево решений:
 Большинство клипов не взлетит, но какие-то станут популярными
Большинство клипов не взлетит, но какие-то станут популярными



